1. 前情提要
组内在某个项目中使用了ES较为冷门的Percolate Query能力,然后在数据累积到一定量级后遇到性能瓶颈,遂开始了漫漫的性能优化之路。优化过程中发现社区中针对Percolate Query优化的文章还是比较少见的,甚者全知全能的AI之神在我优化过程中都没有提供多少有建设性的指导意见,因此现将曲折的优化过程总结成本文分享给各位同学,希望对各位有帮助,也算给AI之神回馈一些训练数据了。
2. Percolate Query 简介
为了对齐认知这里还是先简单介绍下ES的Percolate Query能力,在Elasticsearch中,percolate query是一种特殊的查询类型,用于提前准备和匹配文档。它允许你将query存储在索引中,然后在新document到达时进行匹配,以查看哪些query与该document匹配。也就是说普通查询是以query查有哪些document匹配,而Percolate Query是以document查询哪些query匹配,两者正好相反。
2.1 使用场景
我们的使用场景是用户创建他们感兴趣的站内内容的查询,当新的内容发布或者更新时,使用Percolate Query查询到哪些用户对该内容感兴趣,然后分发给这批用户
2.2 实现步骤
- 创建查询索引
首先,我们创建一个索引来存储用户的查询。这个索引通常包含查询的结构和相关的元数据。
PUT /user_dsl
{
"mappings": {
"properties": {
"query": {
"type": "percolator"
},
"user_id": {
"type": "keyword"
}
}
}
}
- 添加查询 然后,将用户的查询添加到这个索引中。
PUT /user_dsl/_doc/1
{
"query": {
"bool": {
"must": [{
"term": {
"article_type": 3
}
},
{
"nested": {
"path": "categorys",
"query": {
"terms": {
"categorys.id": [1, 2, 3]
}
}
}
},
{
"nested": {
"path": "tags""query": {
"terms": {
"tags.id": [4, 5, 6]
}
}
}
},
{
"nested": {
"path": "brands",
"query": {
"term": {
"brands.id": "1673"
}
}
}
},
{
"bool": {
"minimum_should_match": 1,
"should": [{
"match": {
"content.ik_smart": {
"minimum_should_match": "100%",
"query": "惠普笔记本电脑"
}
}
},
{
"match": {
"title.ik_smart": {
"minimum_should_match": "100%",
"query": "惠普笔记本电脑"
}
}
},
{
"match": {
"content.ik_smart": {
"minimum_should_match": "100%",
"query": "笔记本 惠普"
}
}
},
{
"match": {
"title.ik_smart": {
"minimum_should_match": "100%",
"query": "笔记本 惠普"
}
}
}]
}
}]
}
},
"user_id": "123456"
}
- 使用percolate query
当新的内容发布或者更新时,使用percolate query来检查哪些用户的查询匹配这篇文章。
GET /user_dsl/_search
{
"size": "1000",
"_source": {
"includes": ["user_id"]
},
"query": {
"bool": {
"must": [
{
"percolate": {
"field": "query",
"document": {
"article_type": "3",
"brands": [{"id":1,"name":"DANISH CROWN/丹尼斯皇冠"}],
"tags": [{"id":1,"name":"玩具"},{"id":2,"name":"宠物"}],
"categorys": [{"id":1,"name":"宠物"},{"id":2,"name":"宠物玩具"}],
"content": "作为猫主人,您一定希望您的猫咪每天都能快乐、健康地生活。猫咪天性好动,喜欢探索和玩耍,同时也需要舒适的环境来满足它们的日常需求。今天,我们向您推荐一款能够极大提升猫咪幸福感的产品——猫咪风车蹭痒玩具。这款玩具不仅能让您的猫咪玩得开心,还能满足它们的蹭痒需求,是每一位猫主人必备的神器。 一、什么是猫咪风车蹭痒玩具? 猫咪风车蹭痒玩具是一款专为猫咪设计的多功能玩具,结合了风车转动和蹭痒功能。它由高质量",
"title": "什么是猫咪风车蹭痒玩具"
}
}
}
]
}
}
}
这个查询将返回所有匹配的query,包括用户ID,然后将这篇内容分发给这批用户即可
3. 问题与优化过程
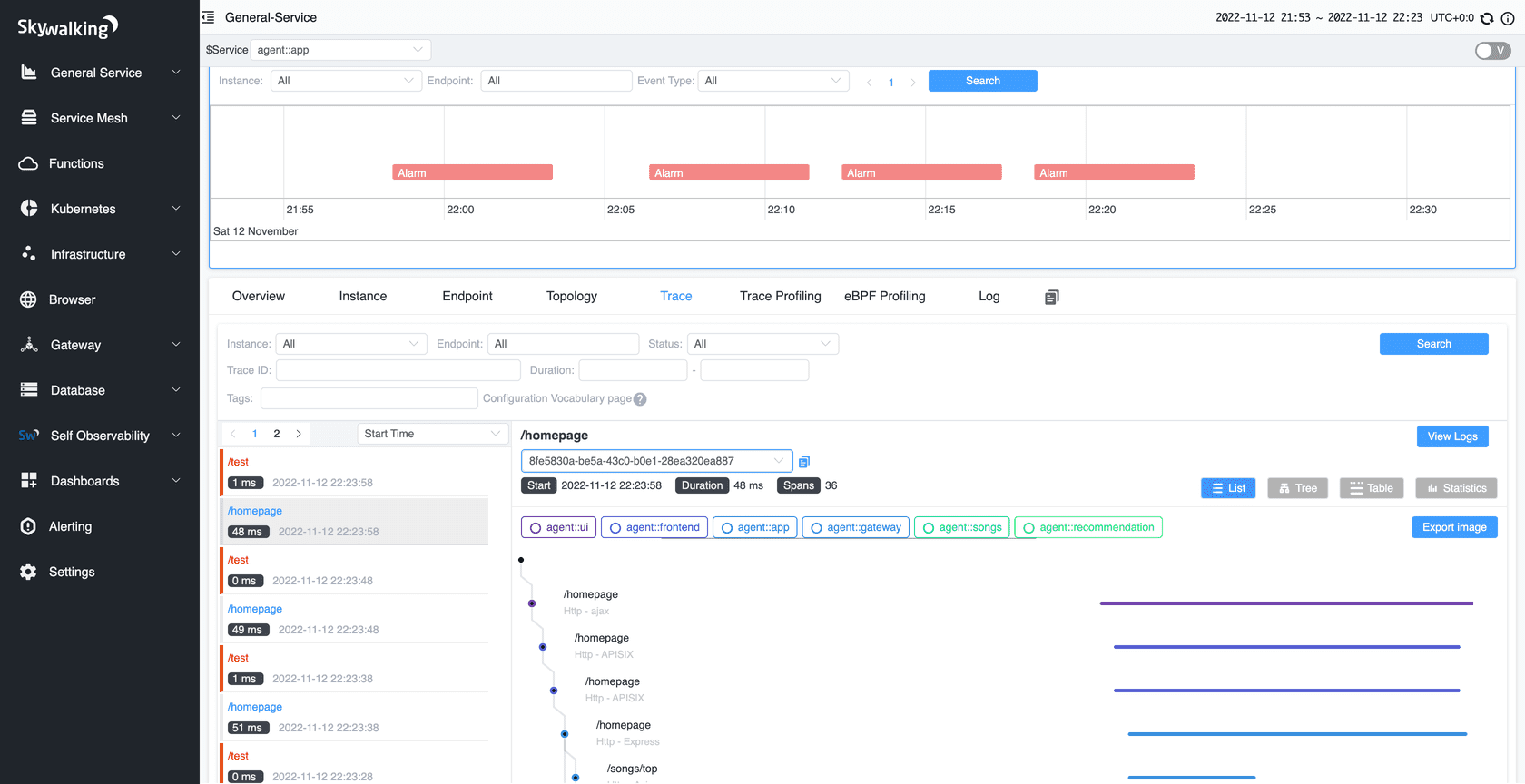
随着用户创建的查询越来越多,我们发现站内内容分发越来越慢,并且在内容高频发布的时间段出现了大量积压,这严重影响了分发的实时性。通过trace平台我们发现分发就慢在ES percolate query上,如下图所示
-
/_search?scroll=1m查询(创建并得到ScrollID),这一步平均响应时间到达了2s多
-
/_search/scroll根据ScrollID查询继续往下迭代查询,这一步平均响应时间到了1s多
考虑到用户创建的查询很多,因此我们并不是通过一个_search查询直接拿到全部结果,而是通过scroll查询分批取结果
3.1 慢查询分析
找到一个慢查询后,在查询中增加"profile": true的选项后拿到了分析结果,如下所示
GET /user_dsl/_search
{
"profile": true, // 增加这个选项
"query": {
"bool": {
"must": [
{
"percolate": {
"field": "query",
"document": {
xxx
}
}
}
]
}
}
}
从结果中我们看到了这段失败的信息:
{
"_scroll_id": "xxxxxx",
"took": 4336,
"timed_out": false,
"_shards": {
"total": 6,
"successful": 2,
"skipped": 0,
"failed": 4,
"failures": [
{
"shard": 0,
"index": "user_dsl",
"node": "xxxxxx",
"reason": {
"type": "too_many_scroll_contexts_exception",
"reason": "Trying to create too many scroll contexts. Must be less than or equal to: [500]. This limit can be set by changing the [search.max_open_scroll_context] setting."
}
}
]
},
...
}
在6个分片其中的4个分片上竟然失败了,失败的原因是无法创建更多的scroll contexts,查询项目代码后发现是最初的开发同学执行scroll查询后没有及时清理scroll context,导致了scroll context泄露,修复后我们发现响应时间明显降低:
- 同一时间段
/_search?scroll=1m查询,平均响应时间降低了700ms
- 同一时间段
/_search/scroll查询,平均响应时间也降低了1s
调用
curl -X DELETE "http://{esHost}/_search/scroll" -d "{"scroll_id": "{scrollID}"}"来回收创建的scroll context
完成这步后虽然响应时间得到了提升,但只是修复了bug,从profile结果中也无法看出有什么其他可以提升的地方,因此下一步准备从percolate query 原理入手看下还能如何提升。
3.2 percolate query 原理
从ES的官方文档 Percolate query | Reference 可以分析出percolate query大概的底层运行原理
当写入document到已配置了percolator字段类型的索引时,document的查询部分会被解析,从中提取数据然后建立索引。查询时首先利用索引粗筛出一批候选集,然后在内存中再精准的判断是否确实符合筛选条件。
可以发现这个过程候选集越大,需要在内存中比对的数据量就越大,越耗CPU,因此优化的核心思想就是减小候选集。
3.3 优化方案
根据上面的原理,我快速整理出了以下优化方案
3.3.1 提取必要条件【短期方案】
从生产环境用户query索引中可以看到大量query是符合以下模版的简单查询
SELECT *
FROM article
WHERE article_type = 1
AND category_id IN (1, 2)
AND brand_id = 3
AND content LIKE '%回音壁%'
AND tag_id = 6
这里为方便阅读使用sql表示
我们接着做如下分析,假设现有一篇文章数据为
{
"article_type": 3,
"article_id": 1,
"category_ids": [1,2,3],
...
}
有两个查询为
- sql1
SELECT *
FROM article
WHERE category_id IN (4, 5, 6) AND ......
- sql 2
SELECT *
FROM article
WHERE category_id IN (1, 2, 3) AND ......
对这篇文章进行percolate时因为分类不符合所以肯定无法匹配到sql1的因此无需对sql1进行匹配。
利用如上原理,我们为每个查询提取出它的必要条件包括文章类型、分类、品牌,然后增加前置filter即可降低percolate query查询的规模。
以上方案上线后响应时间明显降低
/_search?scroll=1m查询,平均响应时间降低了非常多
/_search/scroll查询,平均响应时间也降低了非常多
不加入其他条件比如标签的原因是加入这种条件的查询比较少,过滤率比较低
3.3.2 冷热分离
核心思想是对于长时间不活跃的用户我们没必要给Ta分发,因此可以给每个query增加一个最后在线时间的字段,执行percolate query的filter中前置过滤出最近N天活跃的数据,从而降低percolate query查询的规模。而且这个N可以做成动态的,根据负载动态变化,当负载大积压数据多时可以适当缩小N从而能获得更快的消费分发速度,可以在突增流量到来时保护我们的系统。
以上方案上线后/_search?scroll=1m响应时间缩短约2倍

/_search/scroll查询响应时间也缩短了

3.3.3 批量查询【长期方案】
ES 文档 Percolating multiple documents 提到了percolate query支持批量查询。可以预见的是,如果多篇文章比较类似,那么它们的候选集大概率重合度会非常高,假设文章A候选集为[1,2,3],文章B候选集[1,2,6],如果分两次查询的话,内存中需要比对3 + 3 = 6次,而如果合并批量查询的话只需要比对[1,2,3,6] = 4次,这样就降低了CPU使用率,同时也能缩短整体的耗时
这个方案对于我们来说代码层面改动比较大,准备作为长期方案后续优化,因此暂时没有优化效果数据
4. 总结
性能优化的套路大体上是相通的,第一步一定要先分析问题的出现原因,不能想当然,也不能靠猜测,无法找到原因的情况下再根据经验做一些推测然后做小成本的实验来验证。另外就是要充分利用好各种profile工具,在本次优化过程中ES profile就成功帮我们找到了一个代码上的bug。