1. 前言
几年前给公司前台业务一个QPS很高的接口做了一个优化,主要请求来源是当前在线用户,接口核心逻辑就是从codis中根据一个数字查询对应的用户id(小于1亿),这两个数字的映射关系是不变的,可以理解为codis中有一个map[uint32]uint32的映射表,这个映射表只增不改。
因为接口对codis造成压力很大,因此决定在Go内存中将映射关系缓存下来,但由于这个映射表很大所以不能全部缓存中内存。因此结合业务逻辑决定引入了一个支持LRU淘汰策略的uint32 -> uint32的高性能缓存组件。
调研之后发现市面上Go的各种线程安全还支持LRU的缓存都是有锁的,性能可能受限,因此决定根据应用场景自己搞个特殊的缓存组件。
2. 实现原理
首先还是贴一下源码仓库地址: https://github.com/Orlion/intcache
2.1 结构体定义:
type IntCache struct {
b uint8
buckets [][8]uint64
lruBuckets []uint32
}
func New(b uint8) *IntCache {
cap := 1 << b
return &IntCache{
b: b,
buckets: make([][8]uint64, cap),
lruBuckets: make([]uint32, cap),
}
}
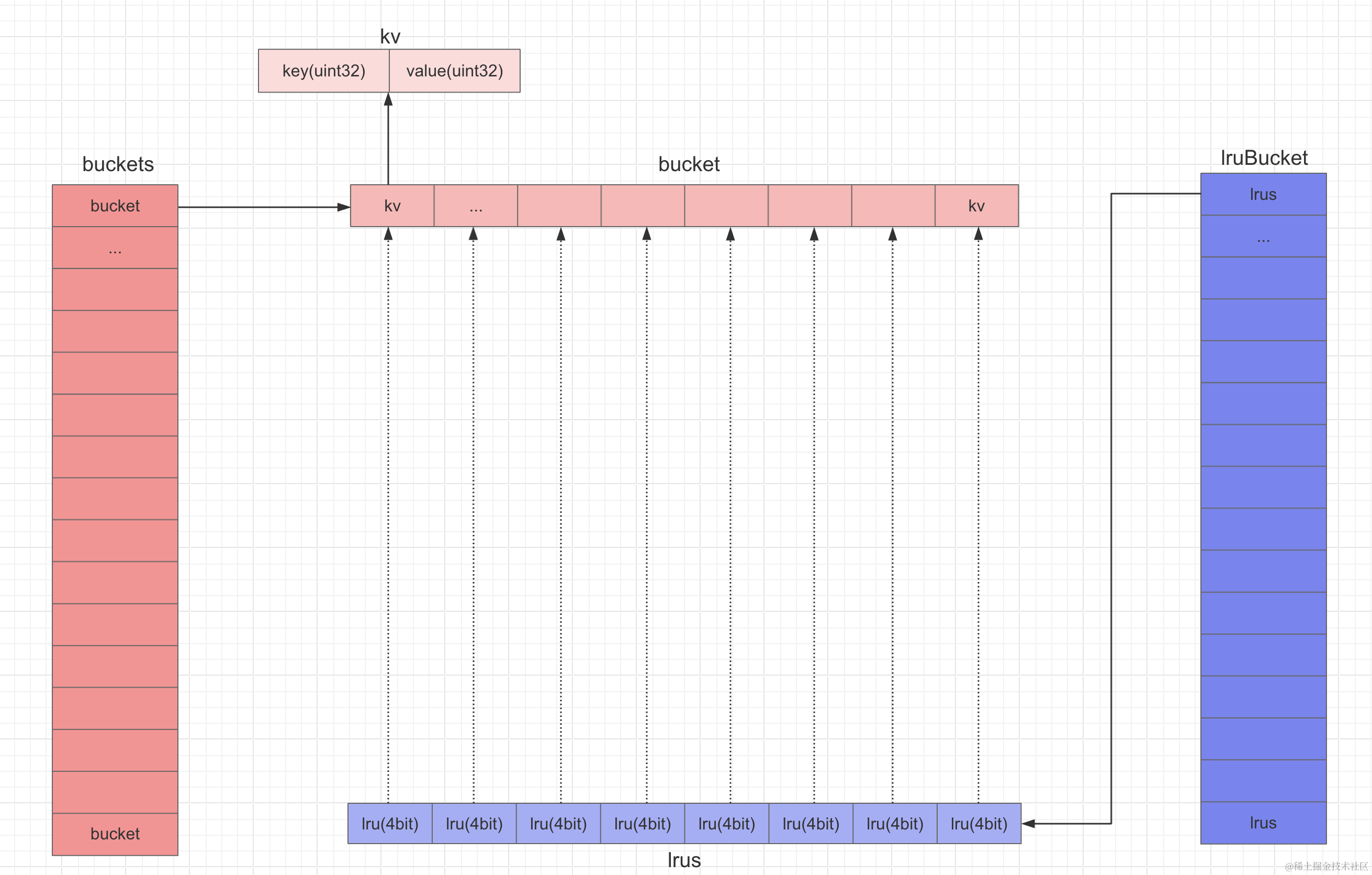
如上图所示,一个IntCache有2^b个bucket和lruBucket,一个bucket有8个K-V对,一个K-V对使用uint64来存储,前32bit存储key,后32bit存储value。一个lruBucket有8个lru值,采用uint32存储,每4bit存储bucket对应的每个K-V对的lru值。
这里你可能会很奇怪为什么lru要单独存储,不要急,继续往下看,读流程时我会详细解释。
2.2 写流程
func (c *IntCache) Set(key uint32, value uint32) {
if key == 0 && value == 0 {
panic("key and value can't be 0")
}
bucketi := key & (1<<c.b - 1)
for i := 0; i < 8; i++ {
e := atomic.LoadUint64(&c.buckets[bucketi][i])
if e == 0 {
atomic.StoreUint64(&c.buckets[bucketi][i], uint64(key)<<32|uint64(value))
c.updLru(bucketi, i)
return
}
if uint32(e>>32) == key {
e = uint64(key)<<32 | uint64(value)
atomic.StoreUint64(&c.buckets[bucketi][i], e)
c.updLru(bucketi, i)
return
}
}
// find the min lru
lrus := atomic.LoadUint32(&c.lruBuckets[bucketi])
var (
minLru uint32
mini int
)
for i := 0; i < 8; i++ {
lru := lrus | 0b1111<<uint32(i)
if lru < minLru {
minLru = lru
mini = i
}
}
atomic.StoreUint64(&c.buckets[bucketi][mini], uint64(key)<<32|uint64(value))
c.updLru(bucketi, mini)
}
写入步骤如下:
- key对容量取模,计算出key落到哪个桶里,然后遍历桶中8个槽(K-V对)
- 如果遍历槽为0,说明这个槽还没有被占用,写入当前槽,并更新lru值为7,其他槽的lru值-1
- 如果遍历槽的key等于当前的key,则更新这个槽的值,并更新lru值为7,其他槽的lru值-1
- 如果遍历完后没有空槽也没有命中key,则找到lru值最小的,淘汰掉然后写入新key并更新lru值
2.3 读流程
func (c *IntCache) Get(key uint32) (value uint32, exists bool) {
bucketi := key & (1<<c.b - 1)
for i := 0; i < 8; i++ {
e := atomic.LoadUint64(&c.buckets[bucketi][i])
if e == 0 {
break
}
if uint32(e>>32) == key {
value = uint32(e)
exists = true
c.updLru(bucketi, i)
break
}
}
return
}
读取步骤如下:
- key对容量取模,计算出key落到哪个桶里,然后遍历桶中8个槽(K-V对)
- 如果遍历到的槽为0,说明后面的槽都是没有数据的,无需继续遍历
- 如果遍历到的槽的key等于查询的key,则返回value,并更新lru值
3. 总结
3.1 为什么lru要单独存储
每个bucket占用8*8=64B,正好是一个x86 cpu cacheline的大小,刚好填满一个cacheline,这样遍历bucket上8个槽实际只需要读取第一个槽时访问一次内存,后续访问都会直接从cpu cache中读到(当然前提是没有写请求造成cacheline过期),这样可以充分利用cpu缓存。
如果lru值与bucket存储在一起,那么系统中大量的读请求修改lru值就会造成cacheline过期的可能性就会变大,而如果分开存储,读请求不会造成cacheline过期。
你可能会问频繁的写入也会造成cacheline过期影响性能啊,但是我们这是一个典型的读多写少的系统,而且大量的bucket也降低了cacheline过期的几率。
3.2 缺陷
3.2.1 适用场景有限
由于我这个组件用在了在线用户访问的场景中,我将bucket数量设置为日活人数/8,hash冲突的几率还是比较小的,从监控看缓存命中率还是比较可观的。
但是由于不是严格的LRU,因此其他业务场景可能不适用。
3.2.2 value与lru值的更新不是原子的
因为要提高cpu cache命中率,因此value更新与lru更新是分离的,无法做到原子性,这也是很不严谨的,但是我们这个业务场景中不需要严谨的lru,所以可以忽略。
4. 基准测试
与fastcache对比的基准测试代码
func BenchmarkIntcache(b *testing.B) {
rand.Seed(1)
var B uint8 = 21
m := New(B)
for i := 0; i < b.N; i++ {
intcacheBenchmarkFn(m)
}
}
func BenchmarkFastcache(b *testing.B) {
rand.Seed(1)
m := fastcache.New(1 << 21 * (64 + 8))
for i := 0; i < b.N; i++ {
fastcacheBenchmarkFn(m)
}
}
func intcacheBenchmarkFn(m *IntCache) {
wg := &sync.WaitGroup{}
for i := 0; i < 1000; i++ {
wg.Add(1)
go func() {
for j := 0; j < 300; j++ {
key := rand.Uint32()
m.Set(key, key)
m.Get(key)
}
wg.Done()
}()
}
wg.Wait()
}
func fastcacheBenchmarkFn(m *fastcache.Cache) {
wg := &sync.WaitGroup{}
for i := 0; i < 1000; i++ {
wg.Add(1)
go func() {
for j := 0; j < 300; j++ {
key := rand.Uint32()
b := make([]byte, 4) // uint64的大小为8字节
binary.LittleEndian.PutUint32(b, key)
m.Set(b, b)
r := make([]byte, 4)
m.Get(r, b)
}
wg.Done()
}()
}
wg.Wait()
}
都是1000个协程并发读写300次,结果:
goos: darwin
goarch: arm64
pkg: github.com/Orlion/intcache
BenchmarkIntcache
BenchmarkIntcache-10 14 78865301 ns/op
BenchmarkFastcache
BenchmarkFastcache-10 10 113746746 ns/op
PASS
ok github.com/Orlion/intcache 9.767s
可以看到我们这个实现要快一点。

...