本文Golang版本为1.13.4
Slice底层结构
go中切片实际是一个结构体,它位于runtime包的slice.go文件中
type slice struct {
array unsafe.Pointer
len int
cap int
}
array是切片用来存储数据的底层数组的指针,len为切片中元素的数量,cap为切片的容量即数组的长度
切片的初始化
创建一个切片有以下几种方式
1. 通过字面量创建
arr1 := [3]int{1,2,3} // 创建一个数组
s1 := []int{1,2,3} // 创建一个len为3,cap为3的切片
上面的创建方式非常容易与数组的另一个创建方式弄混
arr2 := [...]int{1,2,3} // 创建一个数组,数组长度由编译器推断
s1在内存上的结构如下图:

2. 通过make()函数创建
s1 := make([]int, 10) // 创建一个长度为10,容量为10的切片
s2 := make([]int, 5, 10) // 创建一个长度为5,容量为5的切片
s2的内存结构如图:

3. 通过数组/切片创建另一个切片
通过数组/切片创建另一个切片语法为
slice[i:j:k]
其中i表示开始切的位置,包括该位置,如果没有则表示从0开始切;j表示切到的位置,不包括该位置,如果没有j则切到最后;k控制切片的容量切到的位置,不包括该位置,如果没有则切到尾部。下面举几个例子说明:
a := [10]int{0,1,2,3,4,5,6,7,8,9}
s1 := a[2:5:9] // s1结果为[2,3,4], len:3, cap:7
s2 := a[2:5:10] // s2结果为[2,3,4] len:3, cap:8
s3 := a[2:7:10] // s3结果为[2,3,4,5,6] len:5, cap:8
s4 := a[2:] // s4结果为[2,3,4,5,6,7,8,9] len:8, cap:8
s5 := a[:3] // s5结果为[0,1,2] len:3, cap:10
s6 := a[::3] // 编译报错: middle index required in 3-index slice
s7 := a[:] s7结果为[0,1,2,3,4,5,6,7,8,9], len:10, cap:10
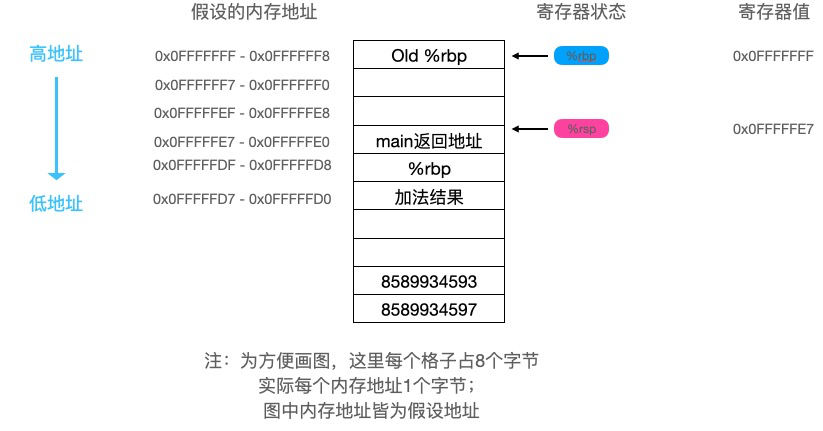
s10 := s1[1:3] s10结果为[3,4], len:2, cap: 6。注意s10的cap是6,而不是7!
s1与s10在内存上的结构如图:

由于a、s1、s2、s3、s4、s5、s7共享同一个数组,所以其中任意一个变量通过索引修改了底层数组元素的值,相当于修改了以上所有变量:
s2[3] = 30
执行上面的代码后:变量a变成了[0,1,2,30,4,5,6,7,8,9]、s1变成了[2,30,4]、…… s7变成了[0,1,2,30,4,5,6,7,8,9]。
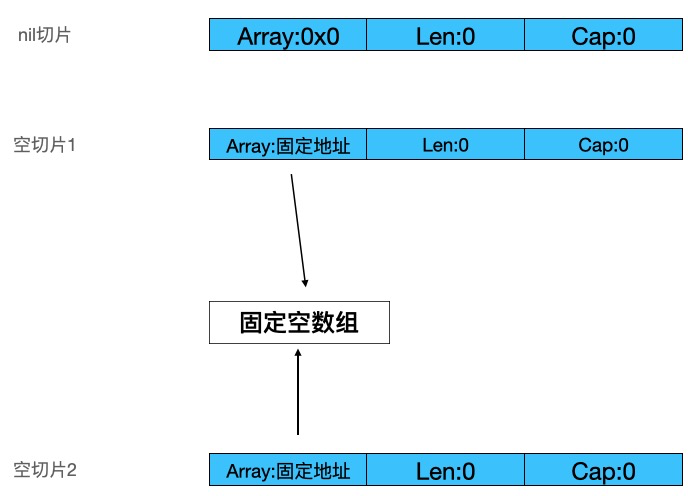
nil切片与空切片
var s11 []int
var s12 = make([]int, 0)
上面的s11为nil,s12是空切片,他们在内存上的结构如图:
我写了段代码验证了下:
var s10 = make([]int, 0)
sh10 := (*reflect.SliceHeader)(unsafe.Pointer(&s10))
println(unsafe.Pointer(sh10.Data))
var s11 []int
sh11 := (*reflect.SliceHeader)(unsafe.Pointer(&s11))
println(unsafe.Pointer(sh11.Data))
var s12 = make([]int, 0)
sh12 := (*reflect.SliceHeader)(unsafe.Pointer(&s12))
println(unsafe.Pointer(sh12.Data))
var s13 = make([]int, 0)
sh13 := (*reflect.SliceHeader)(unsafe.Pointer(&s13))
println(unsafe.Pointer(sh13.Data))
打印结果如下:
0xc00006af08
0x0
0xc00006af08
0xc00006af08
根据打印结果可以看到是上面的结构无误
切片创建源码
我们打印下下面代码对应的汇编,看下golang是如何为我们创建出来一个切片的
func main() {
tttttt := make([]int, 999)
fmt.Println(tttttt)
}
通过go tool compile -S -l slice.go打印对应汇编(-l是禁止内联),下面只摘取关键部分
"".main STEXT size=181 args=0x0 locals=0x48
...
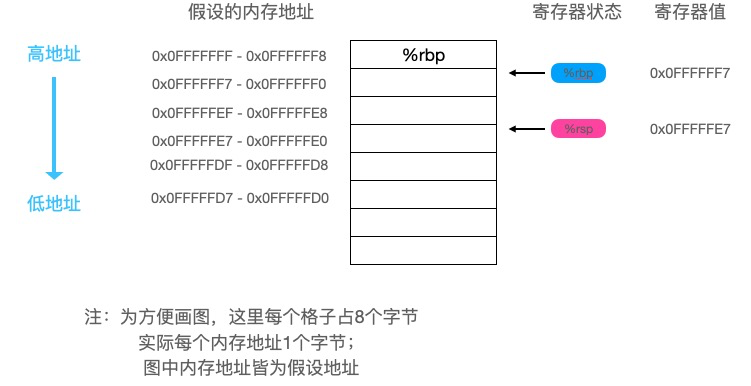
// 栈增加72个字节
0x0013 00019 (slice.go:5) SUBQ $72, SP
// 将当前栈底地址加载到到当前栈顶地址+64处
0x0017 00023 (slice.go:5) MOVQ BP, 64(SP)
// 栈底修改为栈顶地址+64
0x001c 00028 (slice.go:5) LEAQ 64(SP), BP
...
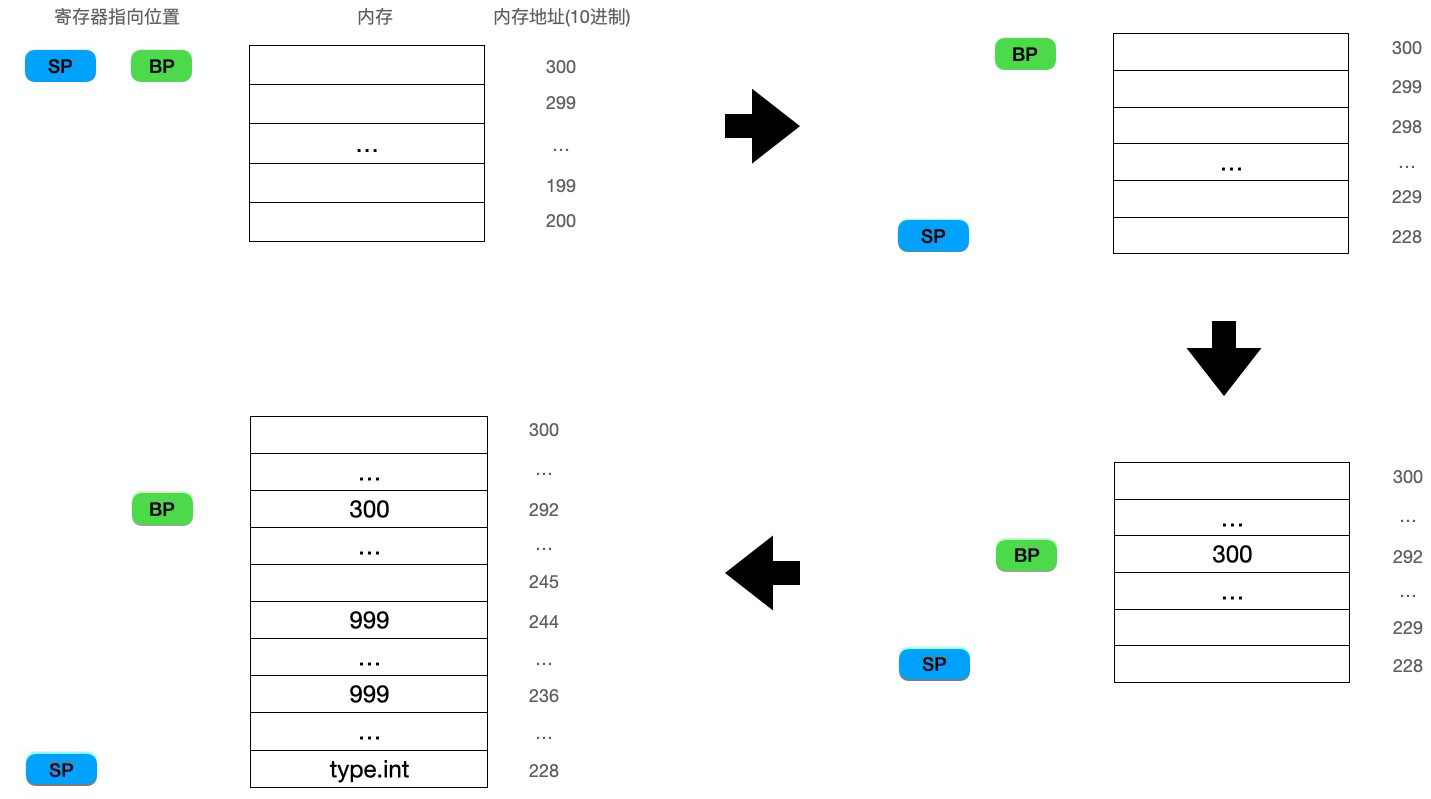
0x0021 00033 (slice.go:6) LEAQ type.int(SB), AX
...
// 下面三行实际是把tuntime.makeslice放到栈上的指定位置
0x0028 00040 (slice.go:6) MOVQ AX, (SP)
0x002c 00044 (slice.go:6) MOVQ $999, 8(SP)
0x0035 00053 (slice.go:6) MOVQ $999, 16(SP)
上面的部分画个图可能更清晰些:
继续看汇编:
// 调用runtime.makeslice函数
0x003e 00062 (slice.go:6) CALL runtime.makeslice(SB)
...
// 将返回值加载到AX寄存器
0x0043 00067 (slice.go:6) MOVQ 24(SP), AX
...
// 下面就是调用fmt.Println函数的代码了
0x0048 00072 (slice.go:7) MOVQ AX, (SP)
0x004c 00076 (slice.go:7) MOVQ $999, 8(SP)
0x0055 00085 (slice.go:7) MOVQ $999, 16(SP)
0x005e 00094 (slice.go:7) CALL runtime.convTslice(SB)
...
0x0063 00099 (slice.go:7) MOVQ 24(SP), AX
...
0x0068 00104 (slice.go:7) XORPS X0, X0
0x006b 00107 (slice.go:7) MOVUPS X0, ""..autotmp_1+48(SP)
...
0x0070 00112 (slice.go:7) LEAQ type.[]int(SB), CX
...
0x0077 00119 (slice.go:7) MOVQ CX, ""..autotmp_1+48(SP)
...
0x007c 00124 (slice.go:7) MOVQ AX, ""..autotmp_1+56(SP)
...
0x0081 00129 (slice.go:7) LEAQ ""..autotmp_1+48(SP), AX
...
0x0086 00134 (slice.go:7) MOVQ AX, (SP)
0x008a 00138 (slice.go:7) MOVQ $1, 8(SP)
0x0093 00147 (slice.go:7) MOVQ $1, 16(SP)
0x009c 00156 (slice.go:7) CALL fmt.Println(SB)
0x00a1 00161 (slice.go:8) MOVQ 64(SP), BP
0x00a6 00166 (slice.go:8) ADDQ $72, SP
0x00aa 00170 (slice.go:8) RET
0x00ab 00171 (slice.go:8) NOP
...
0x00ab 00171 (slice.go:5) CALL runtime.morestack_noctxt(SB)
...
0x00b0 00176 (slice.go:5) JMP 0
上面出现了一个关键函数,即runtime.makeslice,(在堆上分配时才会调用这个函数)我们看下它的实现:
func makeslice(et *_type, len, cap int) unsafe.Pointer {
// 这里实际是计算切片所占的内存大小,即元素的大小乘容量
// mem为所需内存大小,overflow标识是否溢出
mem, overflow := math.MulUintptr(et.size, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
// 如果溢出或者所需内存大于最大可分配内存或者len、cap不合法则报错
mem, overflow := math.MulUintptr(et.size, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
// 调用mallocgc从go内存管理器获取一块内存
return mallocgc(mem, et, true)
}
函数传参
切片作为函数参数传参时实际上是复制了一个runtime.slice结构体,而非是传递的runtime.slice结构体指针,举个栗子:
func main() {
slice := []int{0,1,2}
foo(slice)
}
func foo(slice []int) {
...
}
其实就等价于
type Slice struct {
ptr *[3]int
len int
cap int
}
func main() {
slice := Slice{&[3]int{1,2,3}, 0, 0}
foo(slice)
}
func foo(slice Slice) {
...
}
因为函数的形参与实参共享同一个数组,这就导致当把一个切片作为参数传递到另一个函数时,在函数内修改形参的某个下标的值时也会修改了实参。描述的比较绕,下面看一个实例:
func main() {
param := []int{0, 1, 2}
foo(param)
fmt.Println(param)
}
func foo(arg []int) {
arg[1] = 10
}
打印结果为[0,10,2],原因是param与arg共享同一个底层数组,函数foo内修改了arg[1]实际是将两者的底层数组下标为1的元素修改为了10,所以main函数中的param[1]也就变成了10。
在foo函数内修改arg的len字段,是不会影响到param的len的,下面我们验证下:
func main() {
param := []int{0, 1, 2}
foo(param)
fmt.Println(param)
fmt.Println(len(param))
}
func foo(arg []int) {
arg[1] = 10
argSlice := (*reflect.SliceHeader)(unsafe.Pointer(&arg))
argSlice.Len = 10
fmt.Println(len(arg))
}
打印结果如下:
10
[0 10 2]
3
验证成功。
切片扩容
当通过append函数向切片中添加数据时,如果切片的容量不足,需要进行扩容,实际调用的是runtime包中的growslice()函数
// runtime/slice.go
func growslice(et *_type, old slice, cap int) slice {
...
// 下面就是计算新容量的部分了
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
// 如果所需容量大于当前容量的两倍,则新容量为所需容量
newcap = cap
} else {
// 下面是所需容量<=当前容量两倍的逻辑
if old.len < 1024 {
// 如果当前长度<1024则新容量为当前容量x2
newcap = doublecap
} else {
// 下面是当前长度>=1024的逻辑
// 新容量每次增加自身的1/4,直到超过所需容量
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// 如果溢出则新容量为所需容量
if newcap <= 0 {
newcap = cap
}
}
}
// 此处省略分配内存的代码
...
// p为新分配的底层数组的地址
// 从old.array处拷贝lenmem个字节到p
memmove(p, old.array, lenmem)
// 返回新的切片
return slice{p, old.len, newcap}
}
...















 系统中只有一个redis服务器,所有请求都打到这一台机器上。
随着业务发展,整个系统对redis读的请求量逐渐增加,一台机器逐渐扛不住,所以我们增加了两台从库来分担主库读压力,所以又有了主从架构
系统中只有一个redis服务器,所有请求都打到这一台机器上。
随着业务发展,整个系统对redis读的请求量逐渐增加,一台机器逐渐扛不住,所以我们增加了两台从库来分担主库读压力,所以又有了主从架构 写的请求全部打到Master节点,读的请求分担到Slave节点,Slave是readonly的。
好了,我们现在抗住了较大的读请求,但是这个系统跟上面的单点系统都存在一个问题:Master节点挂掉后,整个系统不可写(因为Slave节点还存活所以系统还可以支撑部分读的请求),导致系统不可用。
虽然可以在发现故障后手动切换Slave节点为Master,但是人工操作还是需要消耗一段时间的,还是不可接受的。我们还需要优化架构提高系统可用性,因为我们引入哨兵机制,使得Master挂点后由Slave节点能够自动切换为Master继续提供服务。
写的请求全部打到Master节点,读的请求分担到Slave节点,Slave是readonly的。
好了,我们现在抗住了较大的读请求,但是这个系统跟上面的单点系统都存在一个问题:Master节点挂掉后,整个系统不可写(因为Slave节点还存活所以系统还可以支撑部分读的请求),导致系统不可用。
虽然可以在发现故障后手动切换Slave节点为Master,但是人工操作还是需要消耗一段时间的,还是不可接受的。我们还需要优化架构提高系统可用性,因为我们引入哨兵机制,使得Master挂点后由Slave节点能够自动切换为Master继续提供服务。


 继续往下看:
继续往下看: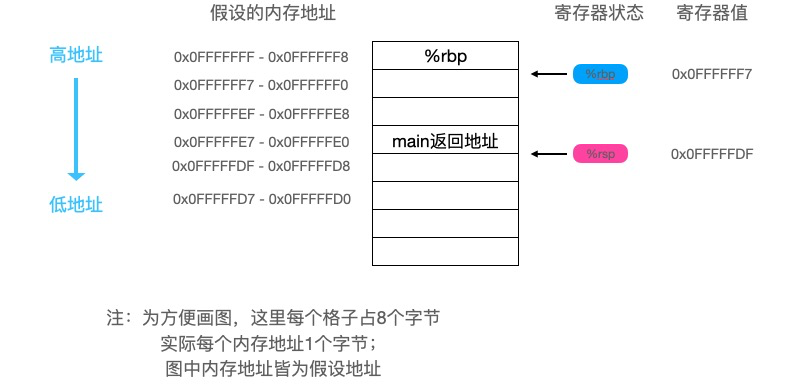
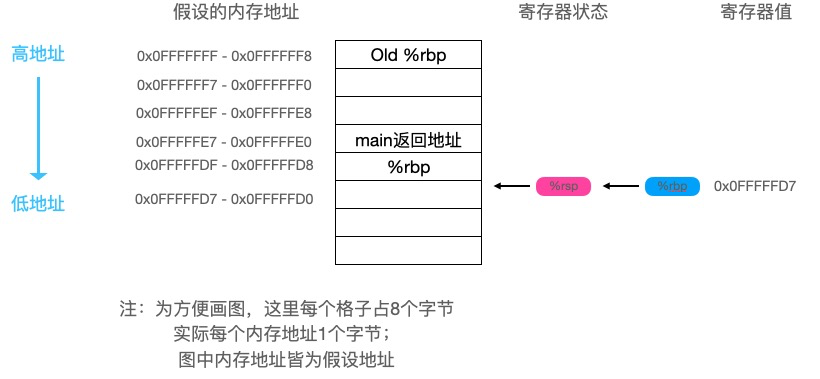
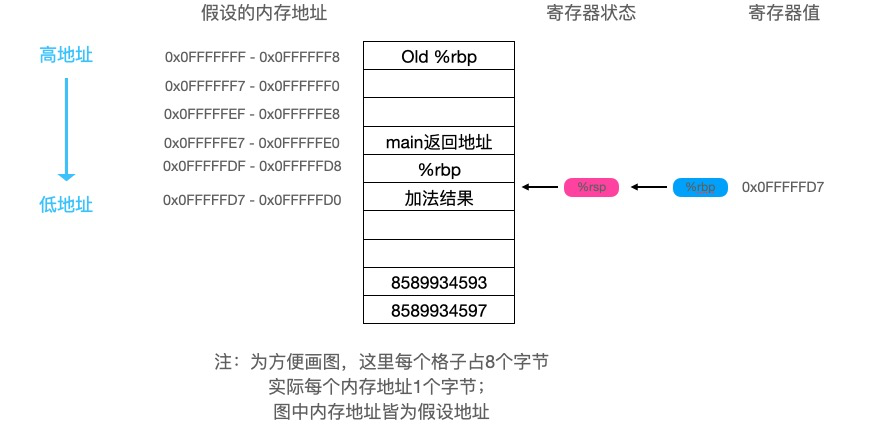 foo函数最后执行了以下两条指令:
foo函数最后执行了以下两条指令: