1. 前言
书接上回 《统计一个数字二进制位1的个数》,现在我们已经知道如何快速计算出一个int64数字的二进制位1的个数,那么回到我们最初的需求,我们的目的是快速统计一个bitmap中二进制位1的个数,假设我们使用[]uint64来实现bitmap,那么如果要统计这个bitmap中二进制位1的个数,我们可以遍历每个元素,计算出每个uint64元素二进制位1的个数,最后加起来,代码大概如下:
type Bitmap []uint64
func (bitmap Bitmap) OnesCount() (count int) {
for _, v := range bitmap {
count += OnesCount64(v)
}
return
}
const m0 = 0x5555555555555555 // 01010101 ...
const m1 = 0x3333333333333333 // 00110011 ...
const m2 = 0x0f0f0f0f0f0f0f0f // 00001111 ...
// 计算出x中二进制位1的个数,该函数上篇文章有详细解释,看不懂可以再回去看下
func OnesCount64(x uint64) int {
const m = 1<<64 - 1
x = x>>1&(m0&m) + x&(m0&m)
x = x>>2&(m1&m) + x&(m1&m)
x = (x>>4 + x) & (m2 & m)
x += x >> 8
x += x >> 16
x += x >> 32
return int(x) & (1<<7 - 1)
}
这种实现方式在bitmap元素过多,切片长度过长的情况下,计算十分耗时。那么如何优化这段代码呢?
2. 优化
现代CPU一般都支持SIMD指令,通过SIMD指令可以并行执行多个计算,以加法运算为例,如果我们要计算{A0,A1,A2,A3}四个数与{B0,B1,B2,B3}的和,不使用SIMD指令的话,需要挨个计算A0+B0、A1+B1、A2+B2、A3+B3的和。使用SIMD指令的话,可以将{A0,A1,A2,A3}和{A0,A1,A2,A3}四个数加载到xmm(128bit)/ymm(256bit)/zmm(512bit)寄存器中,然后使用一条指令就可以同时计算对应的和。这样理论上可以获得N倍的性能提升。
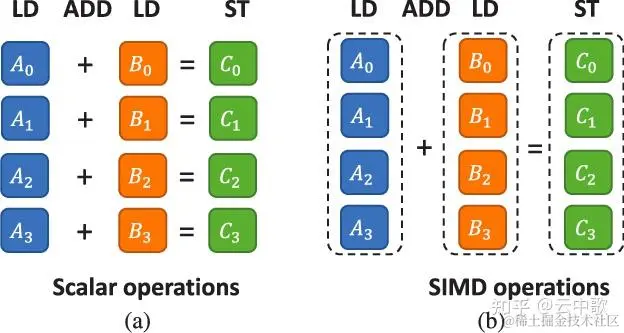
我们可以采用SIMD指令将OnesCount64函数并行化,并行计算4个uint64数字的结果,代码实现如下:
在popcnt.go文件中定义SimdPopcntQuad函数
package popcnt
func SimdPopcntQuad(nums [4]uint64) [4]uint64
在popcnt.s文件中我们使用汇编实现SimdPopcntQuad函数
#include "textflag.h"
TEXT ·SimdPopcntQuad(SB),NOSPLIT,$0-64
VMOVDQU nums+0(FP), Y0 // Y0 = x,将四个uint64数字加载到Y0寄存器
MOVQ $0x5555555555555555, AX
MOVQ AX, X9
VPBROADCASTQ X9, Y5 // Y5 = m0 // 上面三行代码将4个m0加载到Y5寄存器
MOVQ $0x3333333333333333, AX
MOVQ AX, X9
VPBROADCASTQ X9, Y6 // Y6 = m1 // 上面三行代码将4个m1加载到Y6寄存器
MOVQ $0x0f0f0f0f0f0f0f0f, AX
MOVQ AX, X9
VPBROADCASTQ X9, Y7 // Y7 = m2 // 上面三行代码将4个m2加载到Y7寄存器
MOVQ $0x7f, AX
MOVQ AX, X9
VPBROADCASTQ X9, Y8 // Y8 = m;上面三行代码将4个m3加载到Y8寄存器
VPSRLQ $1, Y0, Y1 // Y1 = x>>1;Y0寄存器上四个uint64数字并行右移1位
VPAND Y1, Y5, Y1 // Y1 = x>>1&m0;Y1寄存器上四个uint64数字并行与Y5寄存器上的四个m0并行与,结果存到Y1寄存器
VPAND Y0, Y5, Y2 // Y2 = x&m0
VPADDQ Y1, Y2, Y0 // x = x>>1&m0 + x&m0
VPSRLQ $2, Y0, Y1 // Y1 = x>>2
VPAND Y1, Y6, Y1 // Y1 = x>>2&m1
VPAND Y0, Y6, Y2 // Y2 = x&m1
VPADDQ Y1, Y2, Y0 // x = x>>2&m1 + x&m1
VPSRLQ $4, Y0, Y1 // Y1 = x>>4
VPAND Y1, Y7, Y1 // Y1 = x>>4&m2
VPAND Y0, Y7, Y2 // Y2 = x&m2
VPADDQ Y1, Y2, Y0 // x = x>>2&m2 + x&m2
VPSRLQ $8, Y0, Y1 // Y1 = x >> 8
VPADDQ Y1, Y0, Y0 // x += x >> 8
VPSRLQ $16, Y0, Y1 // Y1 = x >> 16
VPADDQ Y1, Y0, Y0 // x += x >> 16
VPSRLQ $32, Y0, Y1 // Y1 = x >> 32
VPADDQ Y1, Y0, Y0 // x += x >> 32
VPAND Y0, Y8, Y0 // x & (1<<7-1)
VMOVDQU Y0, ret+32(FP) // 将结果加载到内存中返回值的位置
RET
Benchmark
理论上讲如此优化之后我们应该可以获得四倍的性能提升,所以我们写个基准测试验证下:
// 优化之后的并行计算测试
func BenchmarkSimdPopcntQuad(b *testing.B) {
// 使用随机数防止编译阶段被编译器预先计算出来
rand.Seed(time.Now().UnixNano())
nums := [4]uint64{rand.Uint64(), rand.Uint64(), rand.Uint64(), rand.Uint64()}
for i := 0; i < b.N; i++ {
SimdPopcntQuad(nums)
}
}
// 优化之前的顺序计算测试
func BenchmarkSerial(b *testing.B) {
// 使用随机数防止编译阶段被编译器预先计算出来
rand.Seed(time.Now().UnixNano())
nums := [4]uint64{rand.Uint64(), rand.Uint64(), rand.Uint64(), rand.Uint64()}
for i := 0; i < b.N; i++ {
serialPopcntQuad(nums)
}
}
func serialPopcntQuad(nums [4]uint64) [4]uint64 {
return [4]uint64{uint64(bits.OnesCount64(nums[0])), uint64(bits.OnesCount64(nums[1])), uint64(bits.OnesCount64(nums[2])), uint64(bits.OnesCount64(nums[3]))}
}
运行后结果如下
# go test -bench=. -v
=== RUN TestSimdPopcntQuad
--- PASS: TestSimdPopcntQuad (0.00s)
goos: linux
goarch: amd64
pkg: github.com/Orlion/popcnt
cpu: Intel Core Processor (Broadwell, no TSX)
BenchmarkSimdPopcntQuad
BenchmarkSimdPopcntQuad-8 3693530 330.8 ns/op
BenchmarkSerial
BenchmarkSerial-8 539924296 2.232 ns/op
PASS
ok github.com/Orlion/popcnt 2.993s
可以看到优化后的并行计算比原始的顺序计算慢了150倍😭,失败~

3. 分析
虽然优化失败了,但是我们还是要分析复盘下其中的原因,从中汲取一些经验,下面我们从两方面来分析下。
3.1 未优化函数为什么快?
首先我们可以看到未优化的函数serialPopcntQuad计算四个数字竟然只花了2ns,根据Numbers Everyone Should Know一文,访存的时间大概是100ns,这就有点离谱了,计算竟然不从内存加载我们的参数?
下面我们写段main函数,使用随机数来调用下serialPopcntQuad函数,然后反汇编看下汇编代码分析下。
func main() {
rand.Seed(time.Now().UnixNano())
nums := [4]uint64{rand.Uint64(), rand.Uint64(), rand.Uint64(), rand.Uint64()}
results := serialPopcntQuad(nums)
fmt.Println(results)
}
func serialPopcntQuad(nums [4]uint64) [4]uint64 {
return [4]uint64{uint64(bits.OnesCount64(nums[0])), uint64(bits.OnesCount64(nums[1])), uint64(bits.OnesCount64(nums[2])), uint64(bits.OnesCount64(nums[3]))}
}
编译后反汇编:
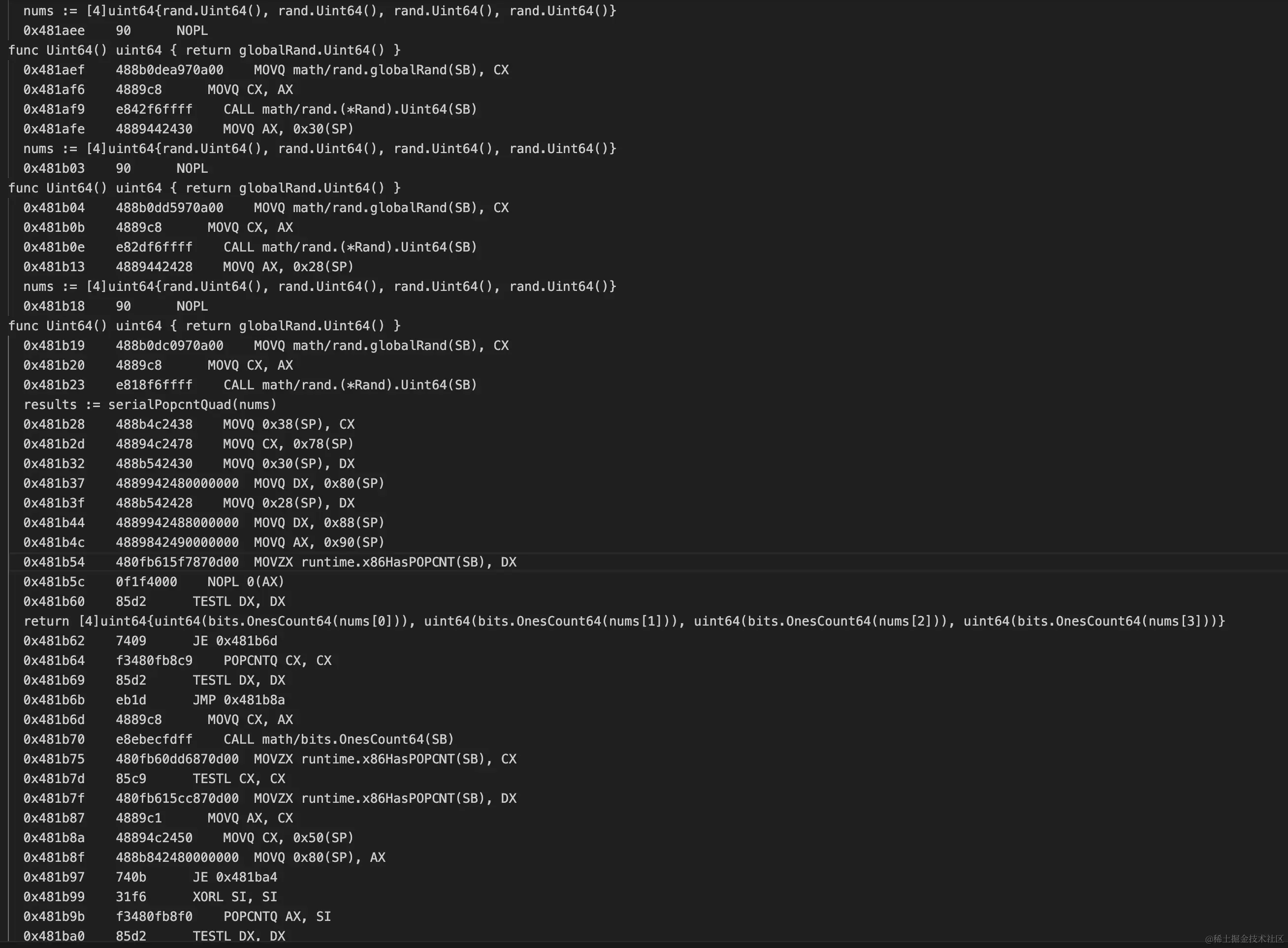
从汇编代码中可以看到在调用bits.OnesCount64之前会判断cpu是否支持popcnt指令,如果支持则使用popcnt指令来计算而不是调用bits.OnesCount64来计算,恰好我机器支持popcnt指令,省略了bits.OnesCount64中的一堆计算,因此计算速度非常快。
3.2 优化后为什么慢?
正如3.1中所提到的,相较于cpu计算,访存的代价是非常高的,大概是100ns,而我们汇编代码中为了使用SIMD指令实现统计算法有大量的访存操作。
受限于本人对汇编掌握程度,上面的汇编代码质量应该是很差的,并不能证明SIMD性能差,可能有性能更高的实现,请各位大佬指点。
而且当前Go汇编在不指定编译参数的情况下只能采用旧函数调用约定,必须采用内存传参,所以导致最终基准测试的结果很差。
4. 收获
这一通瞎折腾虽然最终结果失败,但还是有很多收获的。首先真实的体会到了访存有多慢,所以日后在进行性能优化时就会注意这一点,尽量使代码能命中CPU缓存。
再一个就是之前并没有使用过SIMD指令,也没有接触过这种级别的优化,这次算是入门了。
后端选手,水平有限,各位计算机科学家见笑了。
