通过go mod download下载公司gitlab仓库代码时提示unknown revision 由于是私有仓库且回车执行命令后并没有输入密码的提示,所以猜测是go mod download时git clone 没有输入密码提示
一番搜索后发现解决方案如下:
// 设置永久存储账号密码
git config credential.helper store
// git pull过程中允许输入用户名密码
export GIT_TERMINAL_PROMPT=1
通过go mod download下载公司gitlab仓库代码时提示unknown revision 由于是私有仓库且回车执行命令后并没有输入密码的提示,所以猜测是go mod download时git clone 没有输入密码提示
一番搜索后发现解决方案如下:
// 设置永久存储账号密码
git config credential.helper store
// git pull过程中允许输入用户名密码
export GIT_TERMINAL_PROMPT=1
...
haskell中一般使用data关键字来自定义type,像这样:
data BookInfo = Book Int String [String] deriving (Show)
但有些情况下要使用newtype来定义, 举个例子,对于数字来说,它有两种选择可以表现为一个monoid,一个是 * 作为二元函数,1 作为identity, 另外一种是 + 作为二元函数,0 作为identity。那么问题来了怎么把这两种选择都实现 (这里所说的实现是指把一个数字实现为Monoid这个typeclass的instance) 呢?
Data.Monoid 这个模块导出了两个类型:Product 和 Sum 。Product的定义如下:
Prelude Data.Monoid> :i Product
newtype Product a = Product {getProduct :: a}
Sum的定义如下:
Prelude Data.Monoid> :i Sum
newtype Sum a = Sum {getSum :: a}
Product的Monoid的instance实现:
instance Num a => Monoid (Product a) where
mempty = Product 1
Product x `mappend` Product y = Product (x * y)
很显然它将第一种选择即乘法实现了。它代表 Product a 对于所有属于 Num 的 a 是一个 Monoid
因为newtype比较快。 如果用data的话在执行的时候会有包起来和解开来的成本,但使用newtype的话,Haskell会知道你只是要将一个type包成一个新的type,你想要内部运作完全一样只是要一个新type而已。有了这个概念,Haskell可以将包裹和解开的成本省掉。
为什么不能所有地方都用newtype呢,是因为当使用newtype来制作一个新type的时候,只能有一个值构造器,而且这个值构造器只能有一个字段。
...
为了能真正理解Haskell中的Functor、Applicative、Monad、Monoid,以及它们到底有什么用,个人觉得还是有必要 了解 一些范畴论里面的概念的
函数表示特定类型之间的 态射
自函数就是把类型映射到自身类型
identity :: Number -> Number
identity函数就是一个自函数的例子,它接收什么就返回什么
函子与函数不同,函数描述的是类型之间的映射,而函子描述的是 范畴(category) 之间的映射
范畴是一组类型及其关系 态射 的集合。包括特定类型及其态射,比如: Int、 String、 Int -> String ;高阶类型及其态射,比如 List[Int]、 List[String]、 List[Int] -> List[String]
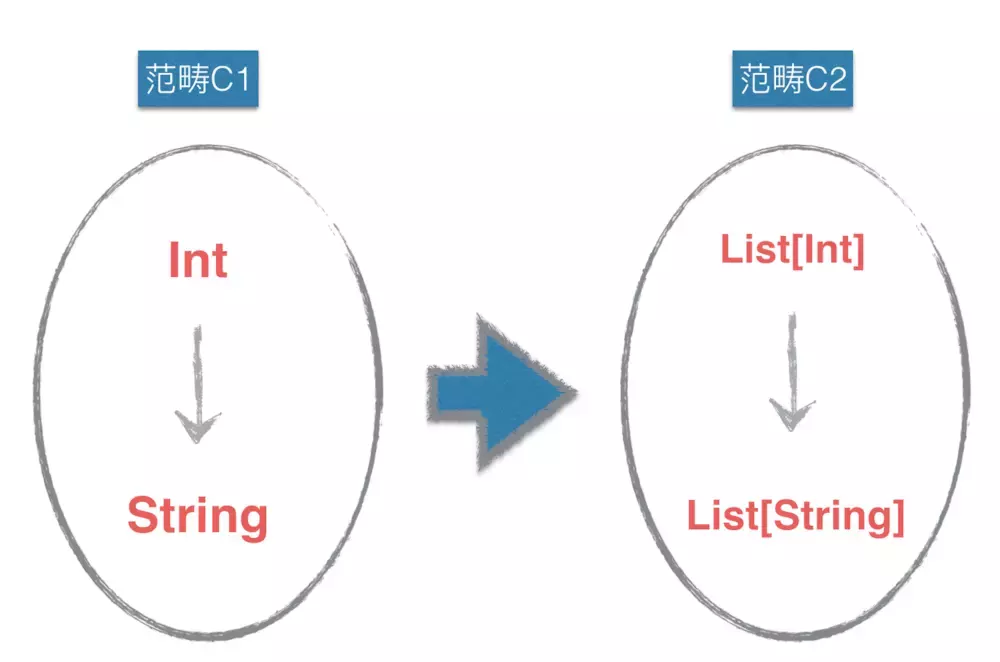
图中,范畴C1和范畴c2之间有映射关系,C1中Int映射到C2List[Int],C1中String映射到C2List[String],C1中的关系态射Int -> String 也映射到 C2中的关系List[Int] -> List[String]态射上。
也就是说,一个范畴内部的所有元素可以映射为另一个范畴的元素,且元素间的关系也可以映射为另一范畴中的元素间的关系,则设为这两个范畴之间存在映射。所谓函子就是表示两个范畴之间的映射。
Haskell中,Functor是可以被map over的东西,List就是一个典型的instance。构造List[Int] 就是把Int提升到List[Int],记作:Int -> List[Int] . 这表达了一个范畴的元素可以被映射为另一个范畴的元素
我们看下Haskell中map函数的定义:
map :: (a -> b) -> [a] -> [b]
把我们上面的Int String的例子代入,配合柯里化的概念可以得出:
map :: (Int -> String) -> (List[Int] -> List[String])
map的定义清晰的告诉我们: Int -> String 这个关系可以被映射为 List[Int] -> List[String] 这种关系。这就表达了元素间的关系可以映射为另外一个范畴元素间的关系
所以List就是一个Functor
自函数是把类型映射到自身类型,那么自函子就是把范畴映射到自身范畴。
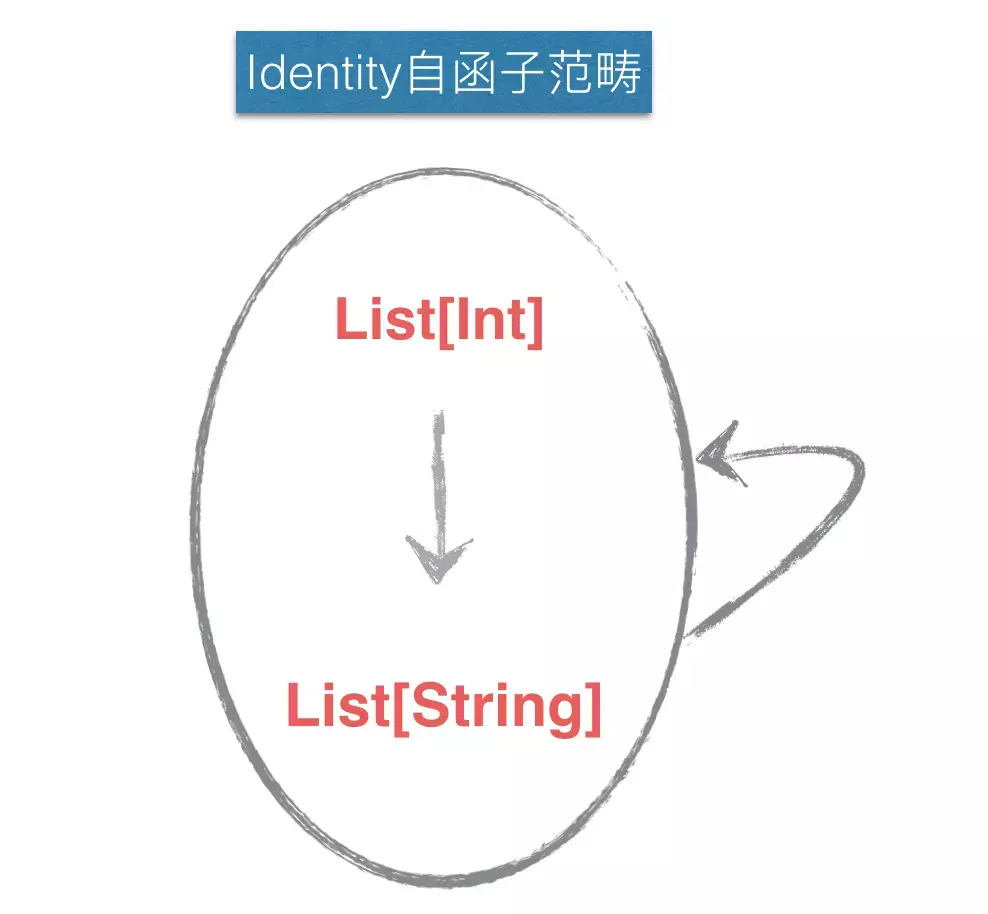
上图就是一个将范畴映射到自身的自函子。从函子的定义出发,我们考察这个自函子,始终有List[Int] -> List[String] 和 List[Int] -> List[String] -> List[Int] -> List[String] 这两种映射。我们表述为:
类型List[Int] 映射到自己
态射f :: List[Int] -> List[String] 映射到自己
我们记作:
F(List[Int]) = List[Int]
F(f) = f
其中F是Functor
先解释下群的概念:G为非空集合,如果在G上定义的二元运算*,满足:
(1) 封闭性:(Closure):对于任意a,b∈G,有a*b∈G
(2) 结合律(Associativity):对于任意a,b,c∈G,有(a*b)*c=a*(b*c)
(3) 幺元 (Identity):存在幺元e,使得对于任意a∈G,e*a=a*e=a
(4) 逆元:对于任意a∈G,存在逆元a^-1,使得a^-1*a=a*a^-1=e
则称(G, *) 为群,简称G为群。
如果仅满足封闭性和结合律,则该G是一个 半群(Semigroup) ; 如果满足封闭性和结合律并且存在幺元,则该G是一个 幺半群(Monoid)。
接下来看下在自函子的范畴上,怎样结合幺半群的定义得出Monad
假设我们有个cube函数,它计算一个数的三次方:
cube :: Number -> Number
现在我们想在其返回值上添加一些调试信息,返回一个元组,第二个元素代表调试信息,函数签名为:
f :: Number -> (Number, String)
可以看到参数与返回值不一致。我们再看下幺半群规定的结合律。对于函数而言,结合律就是将函数以各种结合方式嵌套起来调用。我们将Haskell中的 . 函数看做这里的二元运算。
(.) :: (b -> c) -> (a -> b) -> a -> c
f . f
从函数签名可以看出右边f返回的是元组(Number, String),而左侧的f接收的是Number。所以无法组合,他们彼此不兼容。
有什么办法能消除这种不兼容?结合前面所述,cube是一个自函数,元组(Number,String)在Hask范畴是一个自函子 (这个说法看起来并不准确,(?, String)才应该是一个自函子 ) , 理由如下:
F Number = (Number, String)
F Number -> Number = (Number,String) -> (Number,String)
如果输入和输出都是元组,结果会怎样呢?
fn :: (Number,String) -> (Number,String)
fn . fn
这样是可行的,在验证满足结合律之前,我们引入一个liftM函数来辅助将f提升成fn
liftM :: (Double -> (Double, String)) -> (Double,String) -> (Double, String)
liftM f (x,y) = case r of (n,s) -> (n, y ++ s)
where r = f x
没有验证,就当伪代码看吧
我们来实现元组自函子范畴上的结合律:
cube :: Number -> (Number, String)
cube x = (x * x * x, "cube was called.")
sine :: Number -> (Number, String)
sine x = (Math.sin x, "sine was called.")
f = ((liftM sine) . (liftM cube)) . (liftM cube)
f (3, "")
输出:(0.956, 'cube was called.cube was called.sine was called.')
f1 = (liftM sine) . ((liftM cube) . (liftM cube))
输出:(0.956, 'cube was called.cube was called.sine was called.')
这里f和f1代表的结合顺序产生了相同的结果,说明元组自函子范畴满足结合律。
那如何找到这样一个e,使得 a * e = e * a = a ,此处的 * 就是 .
unit :: Number -> (Number, String)
unit x = (x, "")
f = (liftM sine) . (liftM cube)
f . (liftM unit) = (liftM unit) . f = f
这里的 liftM unit 就是 e 了。
unit 个人理解应该就是类型构造器
...
lambda就是匿名函数,有些时候我们会需要一个函数而这个函数可能只用到一次,并没有重用的场景,我们就可以搞一个 临时 的匿名函数来满足我们的计算。
(\xs -> length xs > 10)
lambda首先是一个\,后面是用空格分隔的参数,->后边就是函数体。通常会用括号括起来。
$函数,也叫作函数调用符,它的定义如下
($) :: (a -> b) -> a -> b
f $ x = f x
普通的函数调用符有最高的优先级,而 $ 的优先级则最低。用空格的函数调用符是左结合的,如 f a b c 与 ((f a) b) c 等价,而 $ 则是右结合的
$是优先级最低的中缀右结合函数,从签名来看,只是个函数调用符,相当于在右边加括号
tip: $是个中缀函数,要求左边是函数,右边是其参数
> max 5 3 * 2 + 1
11
> max 5 $ 3 * 2 + 1
7
f (g (z x)) 与 f $ g $ z x 等价
函数组合用.函数来实现,.函数的定义为:
(.) :: (b -> c) -> (a -> b) -> a -> c
f . g = \x -> f (g x)
函数组合的用处之一就是生成新函数,并传递给其他函数。
假设我们有一个数字组成的list,我们要把它其中每个元素转成负数,在使用函数组合之前我们可能会这样实现:
Prelude> map (\x -> negate (abs x)) [1,2,-3,4,5,-6]
[-1,-2,-3,-4,-5,-6]
tip: 先用abs函数取绝对值,再用negate函数取反
用函数组合的话就可以这样实现:
Prelude> map (negate . abs) [1,2,-3,4,5,-6]
[-1,-2,-3,-4,-5,-6]
函数组合的另一用途就是定义 point free style (也称作 pointless style) 的函数。以下面的函数为例:
sum' :: (Num a) => [a] -> a
sum' xs = foldl (+) 0 xs
等号的两端都有个 xs。由于有柯里化 (Currying),我们可以省掉两端的 xs。foldl (+) 0 回传的就是一个取一 List 作参数的函数,我们把它修改为 sum’ = foldl (+) 0,这就是 point free style。下面这个函数改成point free style就是:
fn x = ceiling (negate (tan (cos (max 50 x))))
fn = ceiling . negate . tan . cos . max 50
...
Prelude> let { lucky' :: Integral a => a -> String; lucky' 7 = "seven"; lucky' x = "other" }
Prelude> lucky' 7
"seven"
Prelude> lucky' 10
"other"
Prelude> lucky' "a"
<interactive>:39:1: error:
• No instance for (Integral [Char]) arising from a use of ‘lucky'’
• In the expression: lucky' "a"
In an equation for ‘it’: it = lucky' "a"
tip: 在8.8.1版本ghci中如果按照书中的写法是会报没有匹配项的错误的,按照let { … } 写法则没有问题
在调用lucky时,模式会从上到下进行检查,一旦有匹配则对应的函数体便被应用。
如果我们制定的匹配模式不全时,传入一个没有被任何模式匹配到的参数时就会报错。
对Tuple同样可以使用模式匹配:
addVectors :: (Num a) => (a, a) -> (a, a) -> (a, a)
addVectors (x1, y1) (x2, y2) = (x1 + x2, y1 + y2)
first :: (a, b, c) -> a
first (x, _, _) = x
List Comprehension 也可以用模式匹配:
Prelude> let xs = [(1,3), (4,3), (2,4), (5,3), (5,6), (3,1)]
Prelude> [a+b | (a,b) <- xs]
[4,7,6,8,11,4]
对List也可以用模式匹配:
Prelude> let {sumList :: Num a => [a] -> a; sumList [] = 0; sumList (x:xs) = x + sumList xs }
Prelude> sumList [1,2,3]
6
bmiTell :: (RealFloat a) => a -> a -> String
bmiTell weight height
| weight / height ^ 2 <= 18.5 = "You're underweight, you emo, you!"
| weight / height ^ 2 <= 25.0 = "You're supposedly normal. Pffft, I bet you're ugly!"
| weight / height ^ 2 <= 30.0 = "You're fat! Lose some weight, fatty!"
| otherwise = "You're a whale, congratulations!"
guard由跟在函数名及参数后边的竖线标志,通常竖线都是靠右一个缩进排成一列。一个guard就是一个布尔表达式,如果是True,就使用对应的函数体。最后的一个guard往往是otherwise,它的定义就是简单一个otherwise = True。
通过guard实现自己的compare函数
-- myCompare.hs
myCompare :: Ord a => a -> a -> Ordering
a `myCompare` b
| a > b = GT
| a < b = LT
| otherwise = EQ
Prelude> :l myCompare.hs
[1 of 1] Compiling Main ( myCompare.hs, interpreted )
Ok, one module loaded.
*Main> 1 myCompare 2
<interactive>:2:1: error:
• Non type-variable argument
in the constraint: Num ((a -> a -> Ordering) -> t1 -> t2)
(Use FlexibleContexts to permit this)
• When checking the inferred type
it :: forall a t1 t2.
(Ord a, Num t1, Num ((a -> a -> Ordering) -> t1 -> t2)) =>
t2
*Main> 1 `myCompare` 2
LT
*Main> 2 `myCompare` 1
GT
*Main> 1 `myCompare` 1
EQ
上面例子中的bmiTell函数weight / height ^ 2重复计算了3次,可以利用where修改:
-- bmiTell.hs
bmiTell :: RealFloat a => a -> a -> String
bmiTell weight height
| bmi <= 18.5 = "case 1"
| bmi <= 25.0 = "case 2"
| bmi <= 30.0 = "case 3"
| otherwise = "otherwise"
where bmi = weight / height ^ 2
*Main> :l bmiTell.hs
[1 of 1] Compiling Main ( bmiTell.hs, interpreted )
Ok, one module loaded.
*Main> bmiTell 130 180
"case 1"
还可以继续修改:
bmiTell :: (RealFloat a) => a -> a -> String
bmiTell weight height
| bmi <= skinny = "You're underweight, you emo, you!"
| bmi <= normal = "You're supposedly normal. Pffft, I bet you're ugly!"
| bmi <= fat = "You're fat! Lose some weight, fatty!"
| otherwise = "You're a whale, congratulations!"
where bmi = weight / height ^ 2
skinny = 18.5
normal = 25.0
fat = 30.0
函数在where绑定中定义的名字只对当前函数可见。 where绑定也可以使用模式匹配
...
where bmi = weihgt / height ^ 2
(skinny, normal, fat) = (18.5, 25.0, 30.0)
where绑定可以定义名字也可以定义函数:
calcBmis :: (RealFloat a) => [(a, a)] -> [a]
calcBmis xs = [bmi w h | (w, h) <- xs]
where bmi weight height = weight / height ^ 2
let绑定是个表达式,允许在任何地方定义局部变量,而对不同的guard不可见。let也可以使用模式匹配
cylinder :: (RealFloat a) => a -> a -> a
cylinder r h =
let sideArea = 2 * pi * r * h
topArea = pi * r ^2
in sideArea + 2 * topArea
let的格式为let [binging] in [expression]。let中绑定的名字仅在in中可见,let中的名字必须对齐在一列。
let是个表达式,而where是个语法结构。因为let是个表达式,所以let可以随处安放:
Prelude> [let square x = x * x in (square 5, square 3, square 2)]
[(25,9,4)]
上面的例子中let定义了一个函数。
若要在一行中绑定多个名字,可以用分号将他们分开:
Prelude> (let a = 100; b = 200; c = 300 in a*b*c, let foo = "Hey"; bar = "there" in foo ++ bar)
(6000000,"Heythere")
tip: 最后那个绑定后面的分号不是必须的,可以加上可以去掉
可以用let改写上面的calcBmis函数:
calcBmis xs = [bmi w h | (w, h) <- xs, let bmi = w / h ^ 2]
List Comprehension 中 let 绑定的样子和限制条件差不多,只不过它做的不是过滤,而是绑定名字。let 中绑定的名字在输出函数及限制条件中都可见。这一来我们就可以让我们的函数只返回胖子的 bmi 值:
calcBmis xs = [bmi | (w, h) <- xs, let bmi = w / h ^ 2, bmi >= 25.0]
在 (w, h) <- xs 这里无法使用 bmi 这名字,因为它在 let 绑定的前面。
在 List Comprehension 中我们忽略了 let 绑定的 in 部分,因为名字的可见性已经预先定义好了。不过,把一个 let…in 放到限制条件中也是可以的,这样名字只对这个限制条件可见。在 ghci 中 in 部分也可以省略,名字的定义就在整个交互中可见。
Prelude> let a = 1
Prelude> a
1
head' :: [a] -> a
head' xs = case xs of [] -> error "No head for empty lists!"
(x:_) -> x
case的语法:
case expression of pattern -> result
pattern -> result
pattern -> result
...
expression匹配符合的模式,如果符合则执行。实际上上面的模式匹配是case的语法糖而已。
函数参数的模式匹配只能用在定义函数时使用,而case可以用在任何地方:
describeList :: [a] -> String
describeList xs = "The list is " ++ case xs of [] -> "empty."
[x] -> "a singleton list."
xs -> "a longer list."
...
ghci中可以用:t检测表达式的类型
Prelude> :t "a"
"a" :: [Char]
函数也有类型,编写函数时给一个明确的类型声明是一个好习惯
removeNonUppercase :: [Char] -> [Char]
removeNonUppercase st = [c | c <- st, c `elem` ['A'..'Z']]
我们可以这样解读这个函数的类型:removeNonUppercase这个函数接收一个Char List类型的参数返回一个Char List类型的返回值
addThree :: Int -> Int -> Int -> Int
addThree x y z = x + y + z
参数之间由->分隔,这样解读这个函数的类型:addThree这个函数接收3个Int类型的参数返回一个Int类型的返回值。
tip: 按照其他语言中的习惯,Int,Int,Int -> Int好像看起来更为恰当一些,但实际haskell中->只有一个作用:它标识一个函数接收一个参数并返回一个值,其中->符号左边是参数的类型,右边是返回值的类型。haskell中所有函数都是只接收一个参数的,所有函数都是currying的。
Tuple的类型取决于它的长度与其中项的类型,空Tuple也是一个类型,它只有一个值()
以head函数为例
Prelude> :t head
head :: [a] -> a
可以看到这里有个a,而a明显不是一个具体的类型,类型首字母必须是大写的,那它是什么呢,它实际上是一个类型变量,a可以是任意类型。
tip: 与其他语言中的泛型generic很像
使用到类型变量的函数被称为“多态函数”。可以这样解读head函数的类型:head函数接收一个a类型的List参数(即任意类型的参数)返回一个a类型的返回值(参数与返回值的类型必须是一样的,都是a类型)
fst函数的类型:
Prelude> :t fst
fst :: (a, b) -> a
可以看到fst取一个包含两个型别的 Tuple 作参数,并以第一个项的型别作为回传值。这便是 fst 可以处理一个含有两种型别项的 pair 的原因。注意,a 和 b 是不同的型别变量,但它们不一定非得是不同的型别,它只是标明了首项的型别与回传值的型别相同。
如果一个类型属于某个typeclass,那它必定实现了Typeclass所描述的行为。
tip: 跟OOP中的接口很像
以==函数的类型声明为例:
Prelude> :t (==)
(==) :: Eq a => a -> a -> Bool
这里的Eq就是typeclass, 这里意思是说a这个type必须是Eq的一个实现(相当于OOP中的a implement Eq)
=>符号左边的部分叫做类型约束
Eq这个Typeclass提供了判断相等性的接口,凡是可比较相等性的类型必定属于Eq class
elem函数的类型为:(Eq a)=>a->[a]->Bool这是因为elem函数在判断元素是否存在于list中时使用到了==的原因。
Show的成员为可用字符串表示的类型,操作Show Typeclass最常用的函数表示show。它可以取任一Show的成员类型并将其转为字符串
Prelude> show [1,2,3]
"[1,2,3]"
Prelude> show True
"True"
Read与Show相反,read函数可以将字符串转为Read的某成员类型
Prelude> read "5" - 2
3
Prelude> read "True" || False
True
但是执行下面的代码,就会提示错误:
Prelude> read "5"
*** Exception: Prelude.read: no parse
这是因为haskell无法推导出我们想要的是一个什么类型的值,read函数的类型声明:
Prelude> :t read
read :: Read a => String -> a
它的回传值属于Read Typeclass,但是如果我们用不到这个值,它就无法推导出这个表达式的类型。所以我们需要在表达式后跟::的类型注释,以明确其类型:
Prelude> read "5" :: Int
5
...
创建doubleMe.hs文件,编写如下代码:
doubleMe x = x + x
保存,打开ghci,输入
Prelude> :l doubleMe.hs
这样我们就加载了我们的doubleMe函数,然后就可以调用这个函数:
Prelude> doubleMe 10
20
tip: 如果修改doubleMe.hs文件需要重新导入的话可以执行:reload doubleMe.hs或者:r doubleMe.hs重新导入
Haskell中的if语句与其他语言不同,else是不可以省略的
doubleSmallNum x = if x > 10 then x else x * 2
Haskell 中的 if 语句的另一个特点就是它其实是个表达式,表达式就是返回一个值的一段代码:5 是个表达式,它返回 5;4+8 是个表达式;x+y 也是个表达式,它返回 x+y 的结果。正由于 else 是强制的,if 语句一定会返回某个值,所以说 if 语句也是个表达式。
列表由方括号以及被逗号间隔的元素组成:
Prelude> [1,2,3]
[1,2,3]
空列表:[],列表中所有元素必须是同一类型。
用 ++ 操作符连接两个list
Prelude> [1,2,3] ++ [4,5,6]
[1,2,3,4,5,6]
用 : 连接一个元素到list头,它读作“cons”即construct简称
Prelude> 1:[2,3]
[1,2,3]
但是[2,3]:1是不被允许的,因为:的第一个参数必须是单个元素,第二个参数必须是list
Prelude> "this is string"
this is string
双引号表示字符串。单个字符用’’表示
Prelude> 't'
t
字符串实际是字符列表,
Prelude> 't' : "his is string"
this is string
Prelude> "this is" ++ " string"
this is string
从list中取值使用!!(相当于其他语言中的arr[index])
Prelude> let l = [1,2,3]
Prelude> l!!1
2
上面的例子就是从列表l中取下标为1的元素
list可以用来装list:
Prelude> let l = [[1,2,3], [1,2,3,4], [1,2,3,4,5]]
haskell不要求每个元素的长度一致,但要求类型必须一致
Prelude> tail [[1,2,3], [1,2,3,4], [1,2,3,4,5]]
[[1,2,3,4], [1,2,3,4,5]]
Prelude> init [[1,2,3], [1,2,3,4], [1,2,3,4,5]]
[[1,2,3], [1,2,3,4]]
Prelude> reverse [1,2,3]
[3,2,1]
Prelude> take 2 [1,2,3]
[1,2]
Prelude> 1 `elem` [1,2,3]
True
可以用列表符号来表示一系列元素,haskell会自动推导:
Prelude> [1..10]
[1,2,3,4,5,6,7,8,9,10]
Prelude> [1.0, 1.25, ..2.0]
[1.0,1.25,1.5,1.75,2.0]
Prelude> [1, 4, 15]
[1, 4, 7, 10, 13]
之所以没有输出15是因为15不属于我们定义的系列元素
Prelude> [x*2 | x <- [1...10]]
[2,4,6,8,10,12,14,16,18,20]
可以给这个comprehension加个限制条件:
Prelude> [x*2 | x <- [1...10], x*2 > 12]
[14,16,18,20]
下面写一个函数,该函数使list中所有>10的奇数变为“BANG“,小于10的奇数变为BOOM:
bangBoom xs = [if x > 10 then "BANG" else "BOOM" | x <- xs, odd x]
tip: odd函数判读x是否是奇数,如果是则返回True
还可以从多个list中取元素:
[x*y | x <- [1,2,3], y <- [4,5,6]]
[4,5,6,8,10,12,12,15,18]
实现自己的length函数:
length' xs = sum [1 | _ <- xs]
_表示我们不会用到这个值
操作含有 List 的 List
Prelude> let xxs = [[1,3,5,2,3,1,2,4,5],[1,2,3,4,5,6,7,8,9],[1,2,4,2,1,6,3,1,3,2,3,6]]
Prelude> [ [ x | x <- xs, even x ] | xs <- xxs]
[[2,2,4],[2,4,6,8],[2,4,2,6,2,6]]
(1,2) (True, "a", 1)
Tuple List:
[(1,2),(3,4),(5,6)]
但是[(1,2),(3,4,5),(5,6)]是会报错的,因为元素类型不一致
两个元素的Tuple可以称为序对(Pair)
Tuple不能是单元素的,因为没有意义
Prudule> fst (1,2,[1,2,3])
1
Prudule> snd (1,2,[1,2,3])
[1,2,3]
Prudule> zip [1 .. 5] ["one", "two", "three", "four", "five"]
[(1,"one"),(2,"two"),(3,"three"),(4,"four"),(5,"five")]
Prudule> zip [5,3,2,6,2,7,2,5,4,6,6] ["im","a","turtle"]
[(5,"im"),(3,"a"),(2,"turtle")]
若是两个不同长度的 List,较长的那个会在中间断开,去匹配较短的那个
...
按照rwh书中模式匹配一节中sumList的例子在ghci敲出这样的代码:
Prelude> sumList (x:xs) = x + sumList xs
Prelude> sumList [] = 0
调用这个函数时是会报一个错误的:
Prelude> sumList [1,2,3]
*** Exception: <interactive>:2:1-14: Non-exhaustive patterns in function sumList
而实际如何要在ghci中做一个模式匹配函数的话应该这样写:
Prelude> let { sumList' [] = 0; sumList' (x:xs) = x + sumList' xs }
Prelude> sumList' [1,2,3]
6
Prelude> :cd /tmp/
Prelude> :show paths
current working directory:
/tmp
module import search paths:
.
使用:cd 命令切换到指定目录
使用:show paths目录查看当前工作目录
...
在看《Haskell趣学指南》这本书的Build Our Own Type and Typeclass一章时,不是很好理解,这里结合《Real World Haskell》这本书做一下记录。
Haskell中使用data关键字来定义新的数据类型:
data BookInfo = Book Int String [String] deriving (Show)
那么如何解读上面的表达式呢? 首先data关键字后边的BookInfo是新类型的名字,我们称BookInfo为类型构造器。类型构造器用于指代(refer)类型。类型名字的首字母必须大写,因此类型构造器的首字母也必须大写。 接下来的Book是值构造器(或者称:数据构造器)的名字,类型的值就是由值构造器创建的。 Book之后的Int String [String] 是类型的组成部分 在这个例子中,Int表示书ID, String表示书名,[String]表示作者
上面的描述其实很像OOP中的累的构造方法,BookInfo部分类似于OOP中的class,上文中的值构造器类似于class的构造方法,Book可以认为是构造方法的方法名,java等一些语言中构造方法是与class是同名的,但是Haskell中很明显没有这种约束,Haskell中类型构造器和值构造器的命名是独立的, 所以其实值构造器是可以与类型构造器同名的,即上面的例子可以写成:data BookInfo = BookInfo Int String [String]
可以将值构造器看作是一个函数:它创建并返回某个类型的值。下面的例子中我们将Int String [String] 三个类型的值应用到Book, 从而创建一个BookInfo类型的值
csapp = Book 123456 "Computer Systems: A Programmer's Perspective" ["Randal E.Bryant", "David R.O'Hallaron"]
使用 :info 命令查看更多关于给定表达式的信息
:info BookInfo
上面BookInfo类型的例子中,Int String [String] 一眼看不出来这三个成分是干什么用的,通过类型别名可以解决这个问题:
type BookId Int
type BookName String
data BookInfo = Book BookId BookName [String]
这样是不是一目了然了呢。
跟golang中的type关键字或者c/c++中的typedef 很像
类型别名也可以有参数
type AssocList k v = [(k,v)]
type IntMap v = Map Int v
type IntMap = Map Int
Bool类型是代数数据类型的一个典型代表,一个代数类型可以有多个值构造器
data Bool = False| True
以此为例我们可以说Bool类型由True值或False值构成 下面是《Haskell趣学指南》中的例子:
data Shape = Circle Float Float Float | Rectangle Float Float Float Float
意思是图形可以是圆形或者是长方形
比较好理解暂不做过多说明,后续再补坑
列表类型是多态的:列表中的元素可以是任何类型。我们也可以给自定义的类型添加多态性。只要在类型定义中使用类型变量就可以做到这一点。Prelude 中定义了一种叫做Mayb的类型:它用来表示这样一种值——既可以有值也可能空缺,比如数据库中某行的某字段就可能为空。
data Maybe a = Nothing | Just a -- Defined in ‘GHC.Maybe’
一个代数数据类型的值构造器可以有多个field,我们能够定义一个类型,其中他的值构造器的field就是他自己,这样我们可以递归的定义下去。我们可以这样定义我们的List:
data List a = Empty | Cons a (List a) deriving(Show,Read,Ord)
用record syntax表示:
data List a = Empty | Cons {headList::a, tailList::List a} deriving(Show,Read,Ord)
ghci> Empty
Empty
ghci> 5 `Cons` Empty
Cons 5 Empty
ghci> 4 `Cons` (5 `Cons` Empty)
Cons 4 (Cons 5 Empty)
ghci> 3 `Cons` (4 `Cons` (5 `Cons` Empty))
Cons 3 (Cons 4 (Cons 5 Empty))
我们可以只用特殊字符来定义函数,这样他们就会自动拥有中缀的性质,同样的我们可以套用在值构造器上,因为他们不过是回传类型的函数而已
infixr 5 :-:
data List a = Empty | a :-: (List a) deriving (Show, Eq, Read, Ord)
定义函数成operator时能够同时指定fixity(不是必须的)。fixity指定了他应该是left-associative还是right-associative,还有他的优先级。infixr是右结合,infixl是左结合,infix无左右优先性。优先级0-9。例:
*的fixity是infixl 7,+的fixity是infixl 6, infixl代表他们都是left-associative,但是*的优先级大于+。
这样我们就可以这样写:
ghci> 3 :-: 4 :-: 5 :-: Empty
(:-:) 3 ((:-:) 4 ((:-:) 5 Empty))
ghci> let a = 3 :-: 4 :-: 5 :-: Empty
ghci> 100 :-: a
(:-:) 100 ((:-:) 3 ((:-:) 4 ((:-:) 5 Empty)))
haskell在deriving Show的时候仍然会视值构造器为前缀函数,因此要用括号括起来
首先看一下Eq是怎么被定义的:
class Eq a Where
(==) :: a->a->Bool
(/=) :: a->a->Bool
x == y = not (x /= y)
x /= y = not (x == y)
tip: 上面的代码是书中给出的而在ghci中打印出来实际是下面这样的:
Prelude> :info Eq
class Eq a where
(==) :: a -> a -> Bool
(/=) :: a -> a -> Bool
{-# MINIMAL (==) | (/=) #-}
-- Defined in ‘GHC.Classes’
instance Eq a => Eq [a] -- Defined in ‘GHC.Classes’
instance Eq Word -- Defined in ‘GHC.Classes’
instance Eq Ordering -- Defined in ‘GHC.Classes’
...
解释下:class Eq a where代表我们定义了一个typeclass叫做Eq,a是一个类型变量,他代表任何我们在定义instance时的类型,接下来我们定义了几个函数,不一定要实现函数但一定要写出函数的类型声明。
下面看下这个类型:
data TrafficLight = Red | Yellow | Green
这里定义了一个红绿灯的类型,该类型目前还不是任何class的instance。虽然通过derive可以让它成为Eq或者Show的instance,但在这里我们手动实现:
instance Eq TrafficLight where
Red == Red = True
Green == Green = True
Yellow == Yellow = True
_ == _ = False
instance关键字用来说明我们定义某个typeclass的instance。
由于==使用/=来定义的,同样/=使用==定义的,所以我们只要在instance中复写其中一个就好了。我们这样叫做定义了一个minimail complete difinition。这是说能让类型符合class行为所最小实现的函数数量。而Eq的minimal complete difinition需要==或者/=实现其中一个。而如果Eq这样定义:
class Eq a where
(==) :: a -> a -> Bool
(/=) :: a -> a -> Bool
当我们定义instance时就需要实现两个函数。所以minimal complete difinition就是==和/=。
我们再来写Show的instance,要满足Show的minimal complete difinition需要实现show函数,它接收一个值返回一个字符串
instance Eq TrafficLight where
show Red = "Red light"
show Yellow = "Yellow light"
show Green = "Green ligth"
可以把typeclass定义成其他typeclass的subclass,Num的class声明就有点长:
class (Eq a) => Num a where
...
我们可以在很多地方加上类型约束,这里就是在class Num where 中的a上加上它必须是Eq instance的约束。其实这可以理解为在定义Num这个class时,必须先定义他为Eq的instance。
Maybe或者List这种与TrafficLight不同,Maybe是一个泛型。它接收一个类型参数(像是Int)从而构造出一个具体的类型。从Eq的typeclass的声明中可以看到a必须是一个具体的类型,而Maybe不是一个具体的类型我们不能写成这样:
instance Eq Maybe where
...
下面的代码虽然Maybe m 是一个具体的类型但是还有一个问题,那就是无法保证Maybe装的东西可以是Eq
instance Eq (Maybe m) where
Just x == Just y = x == y
Nothing == Nothing = True
_ == _ = False
所以还应该加上一个类型约束:
instance (Eq m) => Eq (Maybe m) where
Just x == Just y = x == y
Nothing == Nothing = True
_ == _ = False
大部分情况下class声明中的类型约束都是要让一个typeclass成为另一个typeclass的subclass。而在 instance 宣告中的 class constraint 则是要表达型别的要求限制。
如果想看一个 typeclass 有定义哪些 instance。可以在 ghci 中输入 :info YourTypeClass。所以输入 :info Num 会告诉你这个 typeclass 定义了哪些函数,还有哪些类型属于这个 typeclass。:info 也可以查找类型跟类型构造器的信息。如果你输入 :info Maybe。他会显示 Maybe 所属的所有 typeclass。:info 也能告诉函数的型别宣告。
首先看下Functor这个typeclass
class Functor f where
fmap :: (a -> b) -> f a -> f b
tip: ghci 8.8.1中打印结果如下:
Prelude> :info Functor
class Functor (f :: * -> *) where
fmap :: (a -> b) -> f a -> f b
(<$) :: a -> f b -> f a
{-# MINIMAL fmap #-}
-- Defined in ‘GHC.Base’
instance Functor (Either a) -- Defined in ‘Data.Either’
instance Functor [] -- Defined in ‘GHC.Base’
instance Functor Maybe -- Defined in ‘GHC.Base’
instance Functor IO -- Defined in ‘GHC.Base’
instance Functor ((->) r) -- Defined in ‘GHC.Base’
instance Functor ((,) a) -- Defined in ‘GHC.Base’
可以看到typeclass中的类型变量f并不是一个具体的类型,而是类似于Maybe这样的泛型。从上面我们可以看到fmap接收一个从a类型映射到b类型的函数和一个装有a类型值的functor,返回一个装有b类型值的functor
看下学list时学到的map函数:
Prelude> :t map
map :: (a -> b) -> [a] -> [b]
它接收一个从a类型映射为b类型的函数,和一个装有a类型值的List返回一个装有b类型值的List
是不是很像fmap,不错,List正是一个Functor的instance,而map就是fmap的实现(这一点看下ghci中:info Functor的打印结果就能确认)。
同样的Maybe也是Functor的一个instance:
instance Functor Maybe where
fmap f (Just x) = Just (f x)
fmap f Nothing = Nothing
看到这不免有些疑问,为什么上面instance Eq Maybe where不行在这里写成instance Functor Maybe where就行了呢?原因是Functor要接收的是一个泛型,而不是一个具体的类型。如果把f替换成Maybe,fmap就像是这样:(a -> b) -> Maybe a -> Maybe b,如果像上面将Eq时一样将f替换成Maybe m的话就会成这个样子了:(a -> b) -> Maybe m a -> Maybe m b 这显然是不对的。
如果一个泛型是接收两个参数的呢,以Either a b为例,可以这样写:
instance Functor (Either a) where
fmap f (Right x) = Right (f x)
fmap f (Left x) = Left x
就是把Either a作为Functor的一个instance(Either不能作为Functor的instance)
泛型(型别构造子)接收其他类型作为它的参数来构造出一个具体的类型。这有点像函数,也是接收一个值作为参数并回传另一个值。对于类型如何被套用到泛型上,我们看下正式的定义。
像是3,"abc"或者是takeWhile的值都有自己的类型(函数也是值的一种)。类型是一个标签,值会把它带着,这样我们就能推导出它的性质。但类型也有自己的标签,叫做kind,kind是类型的类型。
我们可以在ghci中通过:k来获取一个类型的kind:
Prelude> :k Int
Int :: *
*代表这个类型是具体类型。一个具体类型是没有任何类型参数的,值只能属于具体类型。*的读法叫做star或是type。
我们再看下Maybe的kind:
Prelude> :k Maybe
Maybe :: * -> *
可以看到Maybe的类型构造子接收一个具体类型(像是Int)然后返回一个具体类型。就像Int -> Int代表这个函数接收Int并返回Int。* -> *代表这个类型构造子接收一个具体类型并返回一个具体类型。我们再对Maybe套用类型参数后再看看它的kind:
Prelude> :k Maybe Int
Maybe Int :: *
...
sudo yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel
sudo yum install gcc perl-ExtUtils-MakeMaker
sudo wget https://github.com/git/git/archive/v2.9.2.tar.gz
sudo tar -zvxf v2.9.2.tar.gz
cd git-2.9.2
sudo make prefix=/usr/local/git all
sudo make prefix=/usr/local/git install
sudo ln -s /usr/local/git/bin/git-upload-pack /usr/bin/git-upload-pack
sudo ln -s /usr/local/git/bin/git-receive-pack /usr/bin/git-receive-pack
sudo groupadd git
sudo useradd git -g git
sudo passwd git
su - git
cd /home/git
mkdir .ssh
chmod 700 .ssh
touch .ssh/authorized_keys
chmod 600 .ssh/authorized_keys
将公钥导入到authorized_keys
cd /data
mkdir gitrepo
chown git:git gitrepo/
cd gitrepo
git init --bare starins.git
chown -R git:git starins.git
git clone ssh://git@ip:port/data/gitrepo/starins.git
...