一、 函数调用相关指令
关于栈可以看下我之前的这篇文章x86 CPU与IA-32架构
在开始函数调用约定之前我们需要先了解一下几个相关的指令
1.1 push
pushq 立即数 # q/l是后缀,表示操作对象的大小
pushl 寄存器
push指令将数据压栈。具体就是将esp(stack pointer)寄存器减去压栈数据的大小,再将数据存储到esp寄存器所指向的地址。
1.2 pop
popq 寄存器
popl 寄存器
pop指令将数据出栈并写入寄存器。具体就是将数据从esp寄存器所指向的地址加载到指令的目标寄存器中,再将esp寄存器加上出栈的数据的大小。
1.3 call
call 立即数
call 寄存器
call 内存
call指令会调用由操作数所代表的地址指向的函数,一般都是call一个符号。call指令会将当前指令寄存器中的内容(即这条call指令下一条指令的地址,也就是函数执行完的返回地址)入栈,然后跳到函数对应的地址开始执行。
1.4 ret
ret指令用于从子函数中返回,ret指令会先弹出当前栈顶的数据,这个数据就是先前调用这个函数的call指令压入的“下一条指令的地址”,然后跳转到这个地址执行。
1.5 leave
leave相当于执行了movq %rbp, %rsp; popq %rbp,即释放栈帧。
二、 函数调用约定
函数调用约定约定了caller如何传参即将实参放到何处,应该按照何种顺序保存,以及callee如何返回返回值即将返回值放到何处。
x86的32位机器之上C语言一般是通过栈来传递参数,且一般都是倒序push,即先push最后一个参数再push倒数第二个参数,并通过ax寄存器返回结果,这称为cdecl调用约定(C有三种调用约定,linux系统中使用cdecl),Go与之类似但是区别在于Go通过栈来返回结果,所以Go支持多个返回值。
x64架构中增加了8个通用寄存器,C语言采用了寄存器来传递参数,如果参数超过。在x64系统默认有System V AMD64和Microsoft x64两种C语言函数调用约定,System V AMD64实际是System V AMD64 ABI文档的一部分,类UNIX系统多采用System V的调用约定。
System V AMD64 ABI文档地址https://software.intel.com/sites/default/files/article/402129/mpx-linux64-abi.pdf
本文主要讨论x64架构下Linux系统的函数调用约定即System V AMD64调用约定。
三、 x64架构下Linux系统函数调用
3.1 如何传递参数
System V AMD64调用约定规定了caller将第1-6个整型参数分别保存到rdi、rsi、rdx、rcx、r8、r9寄存器中,第7个及之后的整型参数从右往左倒序的压入栈中。前8个浮点类型的参数放到xmm0-xmm7寄存器中,之后的浮点类型的参数从右往左倒序的压入栈中。
3.2 如何返回返回值
对于整型返回值要保存到rax寄存器中,浮点型返回值保存到xmm0寄存器中。
3.3 栈的对齐问题
System V AMD64要求栈必须按照16字节对齐,就是说在通过call指令调用目标函数之前栈顶指针即rsp指针必须是16的倍数。之所以要按照16字节对齐是因为x64架构引入了SSE和AVX指令,这些指令要求必须从16的整数倍地址取数,为了兼顾这些指令所以就要求了16字节对齐。
3.4 变长参数
这部分没看懂,待后续发掘。
四、 实际案例分析
4.1 案例1
看下下面这段C代码
unsigned long long foo(unsigned long long param1, unsigned long long param2) {
unsigned long long sum = param1 + param2;
return sum;
}
int main(void) {
unsigned long long sum = foo(8589934593, 8589934597);
return 0;
}
uname -a: Linux xxx 3.10.0-514.26.2.el7.x86_64 #1 SMP Tue Jul 4 15:04:05 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux gcc -v: gcc 版本 4.8.5 20150623 (Red Hat 4.8.5-39) (GCC)
转为汇编代码,gcc -S call.c :
.file "call.c"
.text
.globl foo
.type foo, @function
foo:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movq %rdi, -24(%rbp)
movq %rsi, -32(%rbp)
movq -32(%rbp), %rax
movq -24(%rbp), %rdx
addq %rdx, %rax
movq %rax, -8(%rbp)
movq -8(%rbp), %rax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size foo, .-foo
.globl main
.type main, @function
main:
.LFB1:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movabsq $8589934597, %rsi
movabsq $8589934593, %rdi
call foo
movq %rax, -8(%rbp)
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1:
.size main, .-main
.ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-39)"
.section .note.GNU-stack,"",@progbits
我们先看main函数的汇编代码,main函数中首先执行了三条指令:
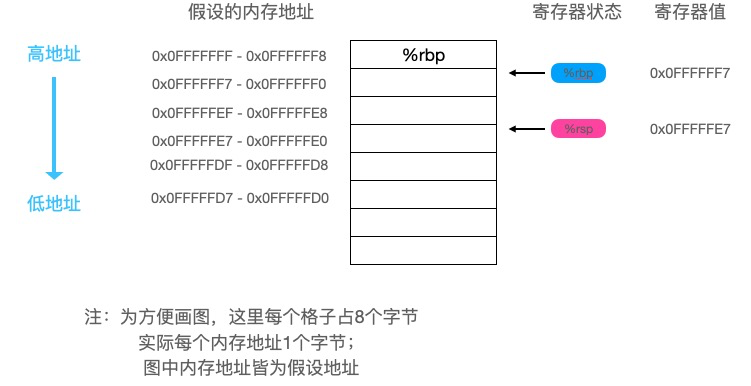
pushq %rbp # 将当前栈基底地址压入栈中
movq %rsp, %rbp # 将栈基底地址修改为栈顶地址
subq $16, %rsp # 栈顶地址-16,栈扩容,这里没搞懂为什么要扩容,有懂的同学欢迎评论区指点下
这三条指令是用来分配栈帧的,执行完成后栈变成下方的样子:
 继续往下看:
继续往下看:
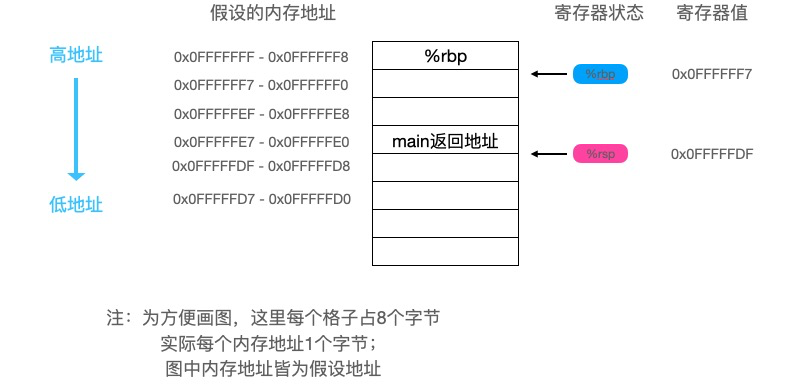
movabsq $8589934597, %rsi # 先将第二个参数保存到rsi寄存器
movabsq $8589934593, %rdi # 再将第一个参数保存到rdi寄存器
call foo # 调用foo函数,这一步会将下一条指令的地址压到栈上
执行完call foo指令后,栈的情况如下:
然后我们跳到foo函数中看下:
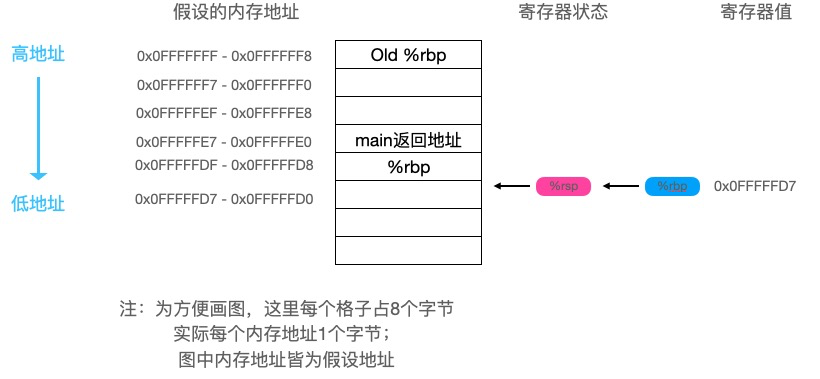
pushq %rbp # 将当前栈基底地址压入栈中
movq %rsp, %rbp # 将栈基底地址修改为栈顶地址
开头仍然是建立栈帧的指令,执行完成后,此时栈帧的样子如下:
继续往下看:
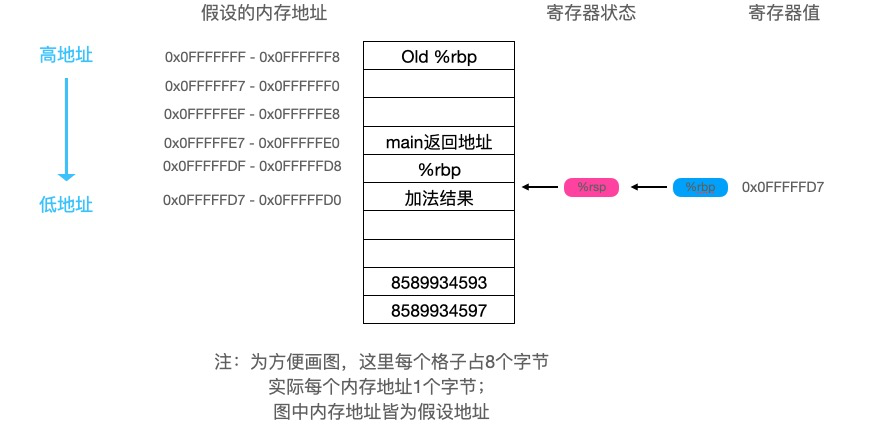
movq %rdi, -24(%rbp)
movq %rsi, -32(%rbp)
movq -32(%rbp), %rax # 将第二个参数保存到rax寄存器
movq -24(%rbp), %rdx # 将第一个参数保存到rdx寄存器
addq %rdx, %rax # 执行加法并将结果保存在rax寄存器
movq %rax, -8(%rbp)
movq -8(%rbp), %rax # 将返回值保存到rax寄存器
这里没搞懂为什么需要先挪到内存中再保存到rax寄存器上,可能是编译器实现起来比较方便吧,有懂的同学欢迎评论区指点下
此时栈情况:
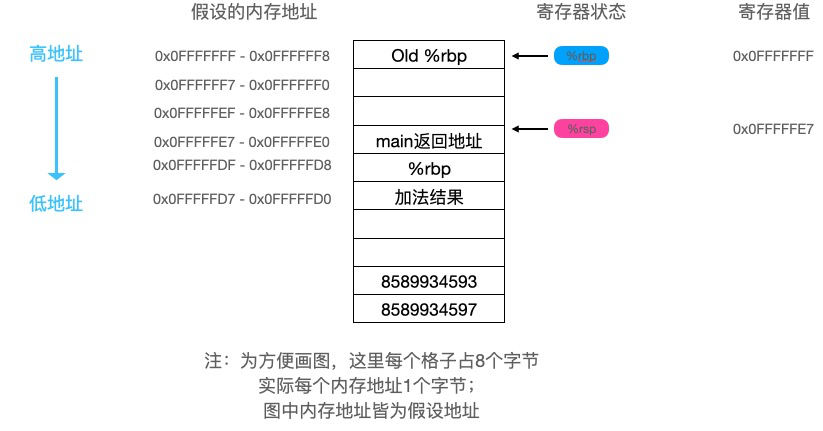
 foo函数最后执行了以下两条指令:
foo函数最后执行了以下两条指令:
popq %rbp # 将栈顶值pop出来保存到rbp寄存器,即修改栈基底地址为当前栈顶值,同时栈顶指针-8
ret # 从子函数中返回到main函数中
最终结果如图:
4.2 案例2
我们修改下函数foo,使它接收9个参数验证下上面的理论。
unsigned long long foo(unsigned long long param1, unsigned long long param2, unsigned long long param3, unsigned long long param4, unsigned long long param5, unsigned long long param6, unsigned long long param7, unsigned long long param8, unsigned long long param9) {
unsigned long long sum = param1 + param2;
return sum;
}
int main(void) {
unsigned long long sum = foo(8589934593, 8589934597, 3, 4,5,6,7,8,9);
return 0;
}
编译为汇编后:
foo:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movq %rdi, -24(%rbp)
movq %rsi, -32(%rbp)
movq %rdx, -40(%rbp)
movq %rcx, -48(%rbp)
movq %r8, -56(%rbp)
movq %r9, -64(%rbp)
movq -32(%rbp), %rax
movq -24(%rbp), %rdx
addq %rdx, %rax
movq %rax, -8(%rbp)
movq -8(%rbp), %rax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size foo, .-foo
.globl main
.type main, @function
main:
.LFB1:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $40, %rsp
movq $9, 16(%rsp) # 后6个参数放到栈上
movq $8, 8(%rsp)
movq $7, (%rsp)
movl $6, %r9d # 前6个参数分别使用rdi rsi rdx ecx r8 r9寄存器
movl $5, %r8d
movl $4, %ecx
movl $3, %edx
movabsq $8589934597, %rsi
movabsq $8589934593, %rdi
call foo
movq %rax, -8(%rbp)
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret







