1. 问题与背景
最近公司内部准备尝试使用下腾讯的TDSQL,因此组内同学写了一段很简单的查询TDSQL的go web程序,使用ab对其进行一个简单压测以获取TDSQL的性能表现,go代码如下:
package main
import (
"crypto/md5"
"database/sql"
"fmt"
"log"
"math/rand"
"net/http"
"strconv"
"time"
"github.com/gin-gonic/gin"
_ "github.com/go-sql-driver/mysql"
)
func main() {
r := gin.New()
r.Use(gin.Logger())
r.GET("/test", func(c *gin.Context) {
c.JSON(200, gin.H{
"message": "test",
})
})
dbconnect, err := sql.Open("mysql", "user:passwd@tcp(10.43.0.43:3306)/dbname")
if err != nil {
panic(err)
}
dbconnect.SetMaxIdleConns(5)
dbconnect.SetMaxOpenConns(10)
dbconnect.SetConnMaxLifetime(time.Hour)
dbconnect.SetConnMaxIdleTime(time.Hour)
r.GET("tdsql_test", func(context *gin.Context) {
muid := fmt.Sprintf("%x", md5.Sum([]byte(strconv.Itoa(rand.Intn(1000000000000)))))
rows, err := dbconnect.Query(fmt.Sprintf("select muid from rtb_channel_0 where muid='%s'", muid))
if err != nil {
log.Fatal(err)
context.JSON(http.StatusInternalServerError, gin.H{
"error_code": -3,
})
return
}
rows.Close()
context.JSON(http.StatusOK, gin.H{
"error_code": 0,
"error_msg": muid,
"data": "result",
})
})
r.Run(":9000")
}
ab压测命令如下:
ab -c 10 -n 500000 "http://127.0.0.1:9000/tdsql_test"
压测开始不久之后代码log.Fatal(err)就打印出了错误信息并退出了:
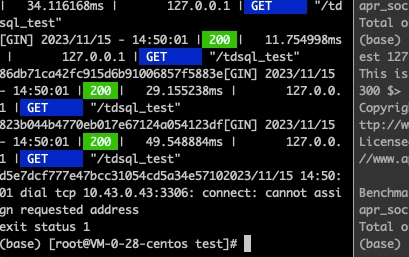
dial tcp 10.43.0.43:3306: connect: cannot assign requested address
这段错误信息是说无法连接到10.43.0.43:3306 ,原因是无法分配请求地址号,就是说本地端口号都被占用了。那么我们就开始进行排查,端口号究竟是被谁占满的?
2. 排查过程
2.1 通过netstat命令查看端口都被谁占用
netstat -nta | grep 10.43.0.43
有如下输出:
 可以看到有大量处于
可以看到有大量处于TIME_WAIT状态的TCP连接,这些连接占用了大量的端口。那么这些TIMI_WAIT状态的TCP连接是从哪来的呢?
为了弄清楚这个问题,我们必须知道TIME_WAIT状态是怎么回事。
2.1.1 TIME_WAIT
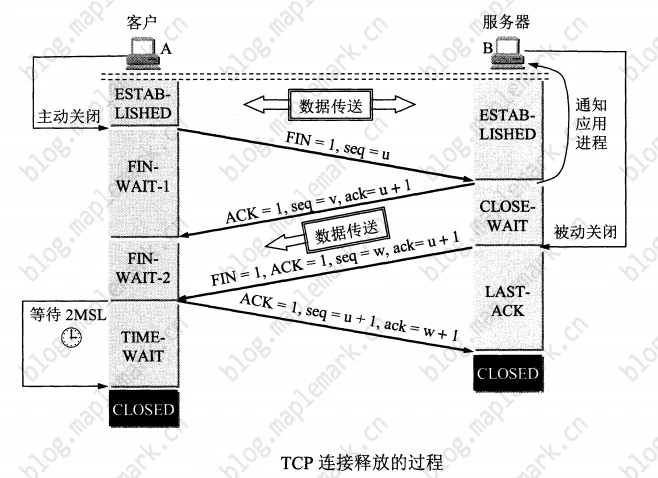
上图是经典的TCP四次挥手断开连接的过程。可以看到在四次挥手的过程中,主动关闭连接的一端在收到对端发送的FIN包之后会进入TIME_WAIT状态,会等待2MSL之后才能真正关闭连接。
MSL: 最长报文段寿命(Maximum Segment Lifetime),是一个工程值(经验值),RFC标准是2分钟,不过有点太长了,一般是30秒,1分钟,2分钟。
为什么客户端TIME_WAIT状态等待2MSL呢?四次握手最后一步客户端向服务端响应ACK,后有两种情况:
- 服务端没有收到ACK,这时服务端会超时重传FIN
- 服务端收到了ACK,但是客户端不知道服务端有没有收到
无论1还是2,客户端都需要等待,要取这两种情况等待的最大值以应对最坏情况的发生,这个最坏的情况就是: 去向ACK消息的最大生存时间(MSL) + 来向FIN消息的最大生存时间(MSL) 。可以看到加起来正好是2MSL。等待2MSL,客户端就可以放心大胆的释放TCP连接了,此时可以使用该端口号连接任何服务器。
如果没有TIME_WAIT,新连接直接复用该连接占用的端口话,恰好回复的ACK包没有达到对端,导致对方重传FIN包,这时新连接就会被错误的关闭。
2.1.2 使用了连接池为什么还会出现大量的TIME_WAIT连接呢
首先大量的TIME_WAIT连接说明了我们的go程序建立了大量的连接然后又关闭了,但是理论上使用了连接池连接都应该得到复用,不会建立大量的连接才对。
这时我首先检查了是不是连接池的ConnMaxLifetime和ConnMaxIdleTime设置的太小导致连接被关闭。我回看了代码发现同事设置了一个小时的时长,那么就不可能是这个原因了。
然后我将怀疑的矛头指向了TDSQL,因为TDSQL是我们首次使用,之前使用Mysql时也没有遇到过这个问题,会不会是TDSQL发送/回复了某个特殊的包导致了客户端主动断开呢?
2.2 验证是否是TDSQL的问题
为了验证上述的猜想,使用tcpdump在服务器上抓了个包
tcpdump -i any host 10.43.0.43 -w output.pcap
然后将抓到的outout.pcap包down下来后丢到本机wireshark中进行分析,选择一个端口过滤下可以看到整个tcp连接的所有包。
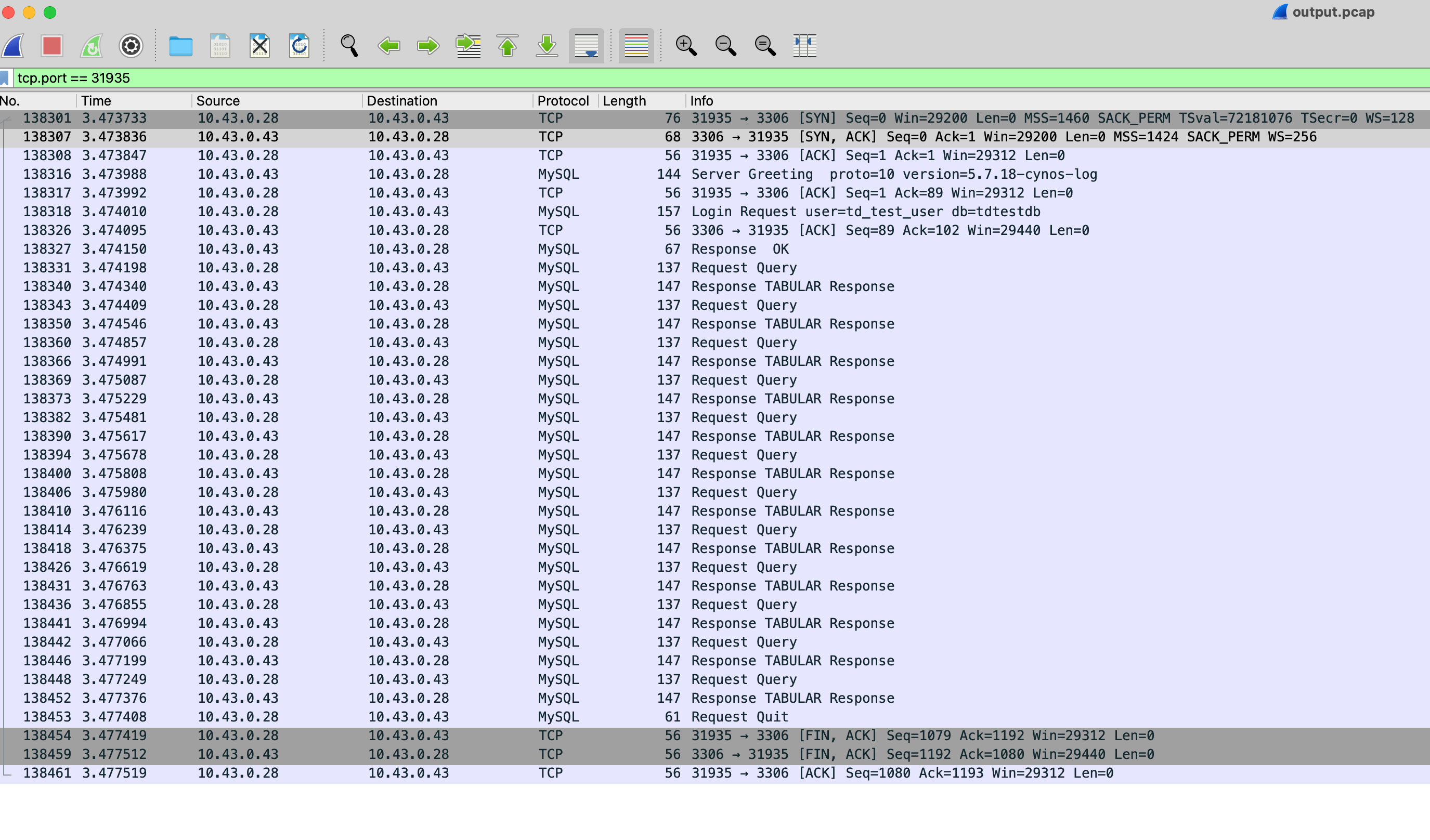
可以看到TDSQL发送的都是正常的mysql协议包,并没有什么特殊的包,因此到这里基本可以确认不是TDSQL的锅。
那么排查的重点又回到了golang连接池,golang连接池为什么会主动断开连接?
2.3 golang为什么会主动断开连接?
由于golang整个sql包非常复杂,我们可以自底向上的思路来排查问题,首先我们找到mysql驱动包go-sql-driver/mysql中关闭连接的函数:
func (mc *mysqlConn) Close() (err error)
它位于connection.go文件中。
下面我们使用dlv 来启动上面的go程序
$ dlv debug main.go
进入到dlv控制台,然后在控制台中输入break mysql.(*mysqlConn).Close在这个函数上打个断点,继续输入c 命令让程序继续执行,然后使用ab命令进行这个web程序进行压测。
不出所料程序断在了mysql.(*mysqlConn).Close。然后我们使用bt命令来打印下调用栈:
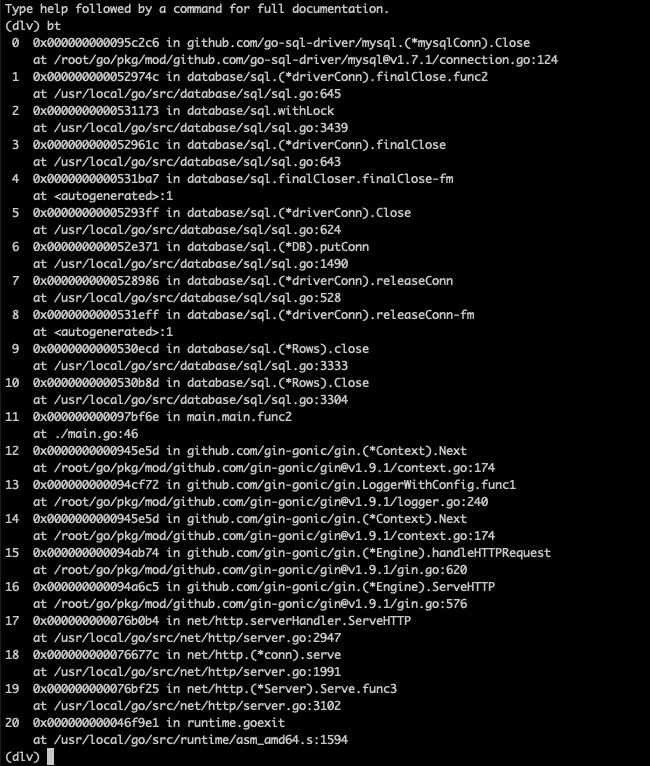
可以清楚的看到整个核心调用链是:
rwos.Close -> driverConn.releaseConn -> DB.putConn -> driverConn.Close -> mysqlConn.Close
问题的关键是DB.putConn ,我们可以分析下源码:
func (db *DB) putConn(dc *driverConn, err error, resetSession bool) {
...
added := db.putConnDBLocked(dc, nil)
db.mu.Unlock()
if !added {
dc.Close()
return
}
}
func (db *DB) putConnDBLocked(dc *driverConn, err error) bool {
if db.closed {
return false
}
if db.maxOpen > 0 && db.numOpen > db.maxOpen {
return false
}
if c := len(db.connRequests); c > 0 {
var req chan connRequest
var reqKey uint64
for reqKey, req = range db.connRequests {
break
}
delete(db.connRequests, reqKey) // Remove from pending requests.
if err == nil {
dc.inUse = true
}
req <- connRequest{
conn: dc,
err: err,
}
return true
} else if err == nil && !db.closed {
if db.maxIdleConnsLocked() > len(db.freeConn) { // db.maxIdleConnsLocked()取自db.maxIdleCount
db.freeConn = append(db.freeConn, dc)
db.startCleanerLocked()
return true
}
db.maxIdleClosed++
}
return false
}
从源码中我们可以得知是DB.putConnDBLocked返回了false导致了连接关闭。为了验证这一点可以继续使用dlv 在dc.Close()这一行打个断点,然后重新压测这个程序:
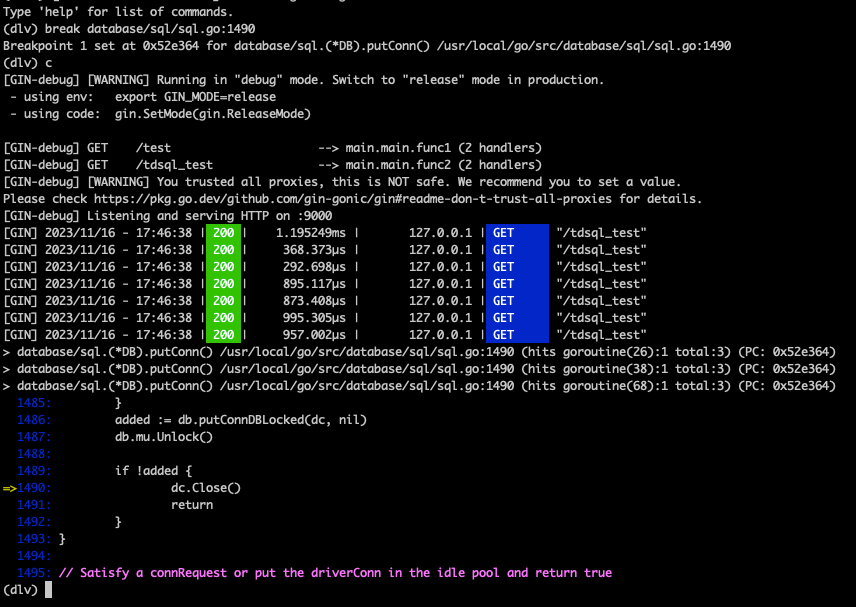 可以看到程序确实是走到了
可以看到程序确实是走到了dc.Close()这一行,我们继续打印上下文的数据:

到这里我们就知道了是由于db.maxIdleCount == len(db.freeConn)导致了连接没有被复用。
db.maxIdleCount是我们代码中设置的dbconnect.SetMaxIdleConns(5)也就是5
那么问题的原因其实就很简单了,我们设置了最大闲置连接数为5,最大可建立连接数为10,那么进程中最多可出现10个连接,这10个连接中只有5个可以被丢回到连接池中复用,而另外5个连接由于超过了我们设置最大闲置连接数5所以不会被丢回到连接池中复用,因此使用完就close了。当并发高的情况下就会出现大量的连接打开与关闭。
3. 解决
最大闲置连接数设置成一个大于等于最大连接数的值即可,比如下面这样:
dbconnect.SetMaxIdleConns(10)
dbconnect.SetMaxOpenConns(10)