背景
最近在研究LSM tree,听闻bitcask在LSM tree各种各样的应用中是一个比较简单的实现,所以就以它为突破口,了解下LSM tree真实世界的实现。
bitcask存储模型由Riak提出,github上有各种语言的实现,本人挑选了一个golang版本的实现来进行研究,源码地址是:git.mills.io/prologic/bitcask,学习过程中我添加了一些注释,有需要的同学可以参考下:github.com/Orlion/bitcask 。
存储模型
与LSM tree的基本思想一样,bitcask中所有增删改操作都是追加写磁盘中的datafile,其数据结构如图:
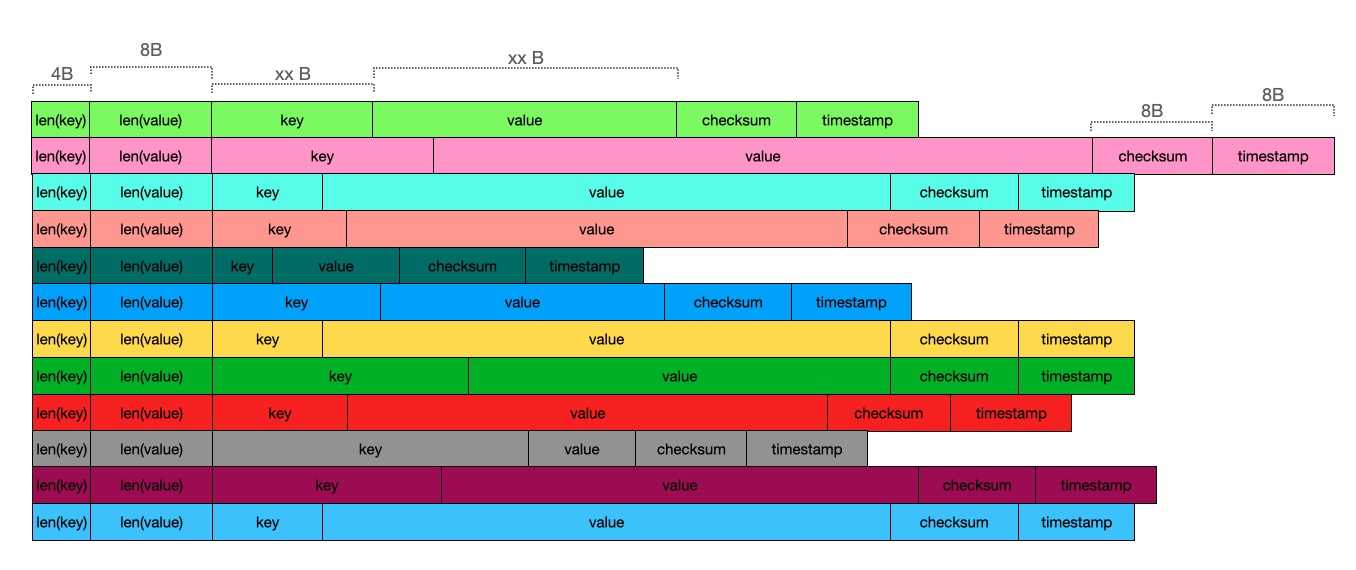
实际文件中是没有换行的,每个entry都是与前一个entry紧密串联在一起的,这里只是为了体现出来一个一个的entry。
datafile由一个一个的entry组成,每个entry的前4个字节存储key的size,第二个8字节存储value的size,然后顺序写入key和value,再写入校验和和过期时间的unix时间戳
datafile写入完成后可以得到新写入项的offset,然后将该key对应的offset与写入的数据项的size写入到内存的索引中,prologic/bitcask索引使用了art即Adaptive Radix Tree(自适应前缀树)作为索引的数据结构,虽然不如hash表查找速度快,但因为是树状结构所以可以支持范围查找。
当datafile写入到一定的大小时会创建一个新的可读可写的datafile,在此之后的新数据会写入到这个新datafile中,老datafile会被设置为只读。因此一个bitcask实例会有多个datafile,所以索引中还必须存储key所在文件的id。
数据结构
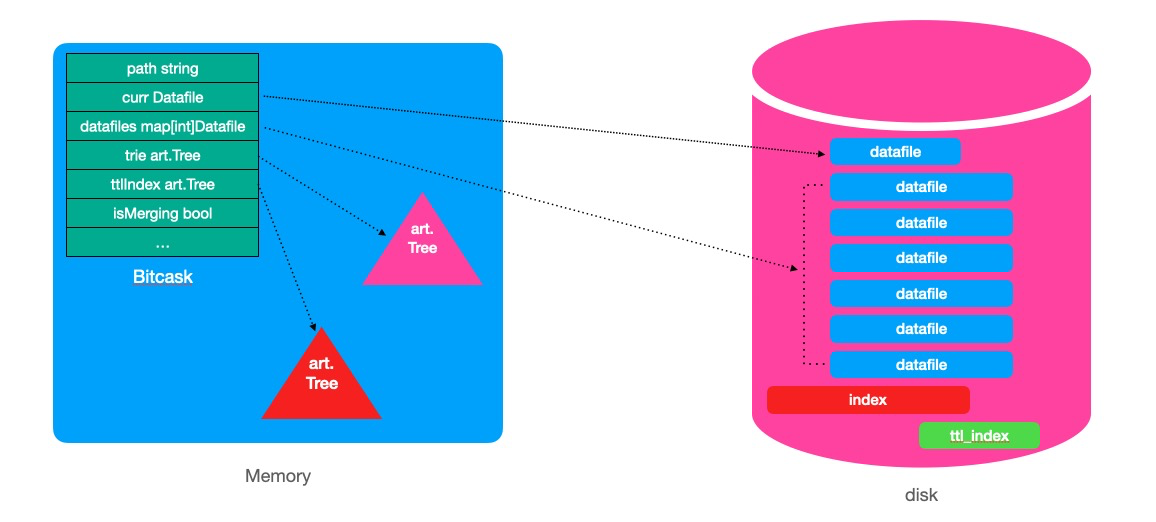
- path指向bitcask的工作目录,即各种文件的存放目录
- curr指向当前可读写的datafile,数据都写入到该文件中
- datafiles 为bitcask持有的所有datafile map,其中key为文件id
- trie和ttlIndex指向内存中的索引树
- isMerging标记当前是否在进行Merge
删除/修改key
上面提到bitcask中删除修改数据也是顺序写磁盘,那么写入的是什么样的数据呢?
实际上,bitcask中修改数据与写入数据是同一个api,即都是Put(key, value []byte),所以修改key也是往datafile中追加写一个新entry,不同是会修改索引中key的指向为最新数据项在文件中的位置。
而删除数据其实就是put(key, []byte{})即向datafile写入空字节切片,写完之后会删除索引中的key。
查找key
get(key)时会先从内存的索引树中根据key找到key所在的文件id和offset以及size,然后通过mmap到对应datafile文件中offset处拉取entry,然后根据前12个字节处的key len与value len数据指示解析出key和value,检查下校验和,自此数据检索完成。
Merge过程
由于bitcask中增删改都是追加写文件,不可避免的磁盘占用会越来越多,所以需要在合适的时机执行merge操作,将old entry和deleted entry从磁盘中清理掉。
bitcask Merge的过程如下:
- 加写锁,判断当前是否有其他线程在执行merge,如果有则退出,如果没有则标记isMerging为true,解锁继续执行
- 加读锁,禁止数据写入,但是可以读
- 当前datafile刷盘,然后关闭当前datafile,将当前dafafile创建为只读datafile加到bitcask实例的datafile列表中,再创建一个新的当前可读写datafile,新的当前文件不执行merge
- 释放读锁
- 在工作目录下创建
merge子目录,以merge目录为工作目录创建merge用的bitcask实例:mdb - 遍历当前bitcask实例索引中的所有key,如果k在要merge的datafiles列表中的话则将k/v写入到mdb中,完成后关闭mdb
- 加写锁,禁止读写
- 关闭当前bitcask实例
- 删除当前工作目录中的所有文件
- 通过rename将mdb工作目录中的所有文件挪到当前工作目录下
- 重新打开实例
- isMerging标记为false,释放写锁,此时可进行读写
索引持久化
上文提到索引是存储在内存中的,这样的话进程重启后索引就需要重新构建,如果数据量多的话,可想而知进程启动得多慢。
所以bitcask中会在以下几个时机将内存中的索引持久化到磁盘中:
- bitcask实例关闭时
- 创建新的datafile之后
索引持久化流程
- 在工作目录中创建临时索引文件temp_index
- 遍历art索引树将节点的 k/item 写入到文件中
- temp_index文件rename为index
索引文件的使用
创建bitcask实例时,会检查工作目录下的索引文件,如果有索引文件,会将索引文件加载到内存中生成art索引树,然后判断索引文件是否是最新的,即索引文件生成后有没有新数据写入,如果不是最新的还需要从最新的datafile中读取数据到索引中。
如果没有索引文件则会遍历所有的datafile,遍历所有数据来构建索引。
总结
可以看到bitcask的实现还是非常简单(lou)的。put(k, v)加了全局锁,锁粒度较粗,并发读写性能应该不是很强。merge的过程要遍历所有的datafile,还要创建新文件,所以对系统的IO压力应该也比较大。