本文使用Golang版本为:go1.13.4
Mutex的使用
先通过一段简单代码看下Go中Mutex的用法
func main() {
a := 1
m := sync.Mutex{}
go func(){
m.Lock()
b := a
a = b + 1
m.Unlock()
}()
m.Lock()
fmt.Println(a)
m.Unlock()
}
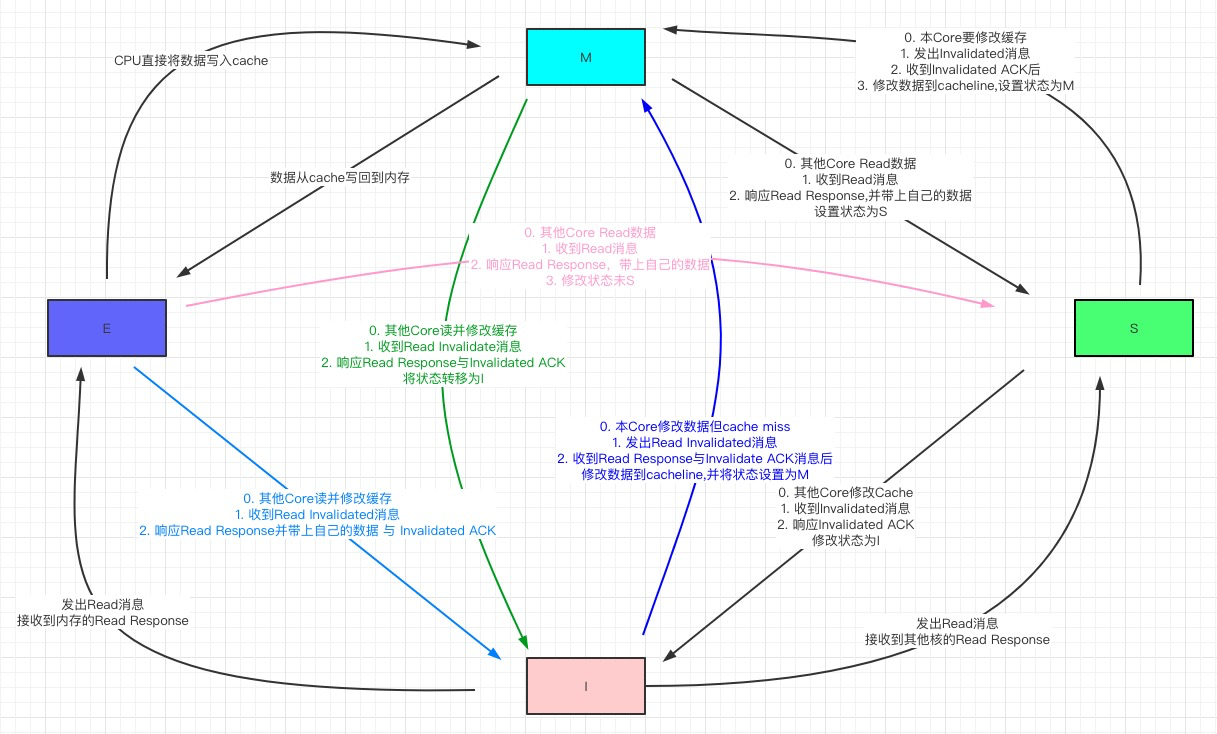
Mutex的设计
在解释Lock()和Unlock()源码之前我们必须先整体了解下Mutex的设计,不然下面的源码很难看懂。
我们首先看下sync.Mutex这个结构体
type Mutex struct {
state int32 // 锁的当前状态,共三种
sema uint32 // 信号量,用于阻塞和唤醒goroutine
}
锁的三个状态,它们使用Mutex.state的低三位来标识
mutexLocked = 1 << iota // 锁定状态,二进制表示即 ...001
mutexWoken // 唤醒状态,二进制表示即 ...010
mutexStarving // 饥饿状态,二进制表示即...100
mutexLocked位于state的第一位,mutexWoken位于state的第二位,mutexStarving位于state的第三位,如下图:

Mutex锁有两种模式:正常模式和饥饿模式。正常模式时,waiter按照先到先得的方式获取锁,一个waiter被唤醒后并不能直接获取到锁,它需要与新到的goroutine抢占锁,但是新到的goroutine已经在CPU上运行了,所以它大概率抢不过新到的goroutine,如果抢不到锁waiter就需要在等待队列队头继续等待,而这可能会导致一个waiter等待很长时间。为了避免waiter等待过久,当waiter超过1ms没有抢到锁时就会将当前锁切换到饥饿模式。
切换到饥饿模式后,锁将从解锁的goroutine切换到等待队列的队头waiter,新来的goroutine不会去尝试获取锁,也不会自旋,它们会排到等待队列的队尾。
如果某waiter获取到了锁,那么在满足以下两个条件之一时,它会将当前锁从饥饿模式切换到正常模式。
- 它是最后一个waiter
- 它等待锁的时间不到1ms
了解了Mutex的设计后我们再继续看Lock()与Unlock()的实现。
加锁Lock()的实现
func (m *Mutex) Lock() {
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
// 这里本有竞争检测的代码,无意义,已被我删除
return
}
m.lockSlow()
}
函数中首先通过CAS操作尝试获得锁,如果m.state为0即当前锁闲置就将它设置为1,如果尝试失败则进入m.lockSlow()。
m.lockSlow()的实现
m.lockSlow()中用到了这几个函数:runtime_canSpin()、runtime_doSpin()、runtime_SemacquireMutex(),我们先挨个解释下这几个函数的作用再看m.lockSlow()的源码。
runtime_canSpin()
该函数的作用是判断能够进入自旋,下面看下源码
// Active spinning for sync.Mutex.
//go:linkname sync_runtime_canSpin sync.runtime_canSpin
//go:nosplit
func sync_runtime_canSpin(i int) bool { // i是当前自旋次数
if i >= 4|| ncpu <= 1 || gomaxprocs <= int32(sched.npidle+sched.nmspinning)+1 {
return false
}
if p := getg().m.p.ptr(); !runqempty(p) {
return false
}
return true
}
通过这个函数我们可以看到,runtime层判断能够自旋必须满足以下几个条件
- 当前自旋次数不能>=4
- 必须是多核CPU
- 至少有一个其他正在运行的P
- 当前P本地G队列为空
这里解释下gomaxprocs <= int32(sched.npidle+sched.nmspinning)+1这个条件:
gomaxprocs是进程中P数量上限,sched.npidle是空闲的P的数量、sched.nmspinning是自旋中的M的数量gomaxprocs - sched.npidle - sched.nmspinning=当前运行中的P的数量,当前运行中的P数量-1(当前P) = 其他P的数量,所以这个条件就是至少有一个其他正在运行的P。
runtime_doSpin()
其源码为:
//go:linkname sync_runtime_doSpin sync.runtime_doSpin
//go:nosplit
func sync_runtime_doSpin() {
procyield(30)
}
这里我们仅看下AMD64平台上proyield的实现:
TEXT runtime·procyield(SB),NOSPLIT,$0-0
MOVL cycles+0(FP), AX // 将第一个参数即30加载到AX寄存器
again:
PAUSE // CPU空转,达到占用CPU的效果
SUBL $1, AX // AX寄存器-1
JNZ again // 如果不为0则继续执行PAUSE指令,否则退出
RET
到这里可以看出runtime_doSpin()实际就是CPU空转30次。
runtime_SemacquireMutex()
其实现位于runtime包的sema.go文件中
//go:linkname sync_runtime_SemacquireMutex sync.runtime_SemacquireMutex
func sync_runtime_SemacquireMutex(addr *uint32, lifo bool, skipframes int) {
semacquire1(addr, lifo, semaBlockProfile|semaMutexProfile, skipframes)
}
semacquire1的实现并非本文重点,这里大概解释下这个函数的作用:
- 如果lifo为true,则加到等待队列队头
- 如果lifo为false,则加到等待队列队尾
m.lockSlow()
了解了上面几个函数后我们来看下m.lockSlow()中是怎么处理的吧
func (m *Mutex) lockSlow() {
var waitStartTime int64
starving := false // 饥饿模式标志
awoke := false // 唤醒标志
iter := 0 // 已进行的自旋次数
old := m.state // 保存当前锁状态
for {
// 进入自旋需要满足三个条件
// 1. 当前锁状态是锁定状态,如果不是锁定状态就退出自旋尝试获取锁
// 2. 当前不是饥饿状态,原因是饥饿状态时自旋无意义,因为锁会交给等待队列中的第一个waiter
// 3. runtime_canSpin判断能够自旋
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
// 如果没有唤醒 且 当前锁状态不在唤醒状态
// 且 当前有等待者则尝试通过CAS将锁状态标记为唤醒
// 标记为唤醒后,Unlock()中就不会通过信号量唤醒其他锁定的goroutine了
// 如果CAS成功则标识自己为唤醒
awoke = true
}
// CPU空转30次
runtime_doSpin()
// 自旋次数+1
iter++
// 更新当前锁状态
old = m.state
// 继续尝试自旋
continue
}
// 如果判断不能进入自旋则进入以下逻辑
// 进到这里有三种情况:
// 1. 当前已解锁,锁处于正常状态
// 2. 当前已解锁,锁处于饥饿状态
// 3. 当前未解锁,锁处于正常状态
// 4. 当前未解锁,锁处于饥饿状态
// old是锁的当前状态,new是期望状态,在下面会尝试将锁通过CAS更新为期望状态
new := old
if old&mutexStarving == 0 {
// 如果当前锁是正常状态则尝试获取锁
new |= mutexLocked
}
if old&(mutexLocked|mutexStarving) != 0 {
// 等待数+1
// 如果锁当前处于饥饿状态,当前goroutine不能获取锁,需要进到等待队列队尾排队等待,所以等待数需要+1
// 如果当前锁处于锁定状态,也需要进到等待队列等待
new += 1 << mutexWaiterShift
}
if starving && old&mutexLocked != 0 {
// 如果当前处于饥饿模式并且锁定状态
// 则尝试设置为饥饿状态
new |= mutexStarving
}
if awoke {
if new&mutexWoken == 0 {
// 如果当前goroutine抢到了唤醒,但是唤醒标志还为0说明出现了异常情况
throw("sync: inconsistent mutex state")
}
// 如果在自旋时当前goroutine抢到唤醒了,则尝试将锁标记为未唤醒
new &^= mutexWoken
}
// 尝试将锁状态由旧状态修改为期望状态
if atomic.CompareAndSwapInt32(&m.state, old, new) {
// 修改成功
// 如果旧状态既不是锁定状态也不是饥饿状态
// 说明了抢到了锁,则退出循环
if old&(mutexLocked|mutexStarving) == 0 {
break
}
queueLifo := waitStartTime != 0
if waitStartTime == 0 {
// 记录等待开始时间
waitStartTime = runtime_nanotime()
}
// 通过信号量阻塞当前goroutine
// 如果waitStartTime为0,则说明当前goroutine是一个新来的goroutine,那么queueLifo=false,意味加到队尾。
// 如果waitStartTime不为0,意味当前goroutine是一个被唤醒的goroutine,那么queueLifo=true,意味着加到队头
runtime_SemacquireMutex(&m.sema, queueLifo, 1)
// 如果等待时间超过了1ms则切换到饥饿模式
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
// 更新当前锁状态
old = m.state
// 如果当前锁处于饥饿状态
if old&mutexStarving != 0 {
// 如果当前锁处于锁定状态或者唤醒状态或者没有waiter,异常
if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 {
throw("sync: inconsistent mutex state")
}
// 因为当前goroutine已经获取了锁,delta用于将等待队列-1
delta := int32(mutexLocked - 1<<mutexWaiterShift)
// 如果当前不是锁定模式或者只有一个waiter
// 就通过delta -= mutexStarving和atomic.AddInt32操作将锁的饥饿状态位设置为0,表示为正常模式
if !starving || old>>mutexWaiterShift == 1 {
delta -= mutexStarving
}
atomic.AddInt32(&m.state, delta)
break
}
awoke = true
iter = 0
} else {
old = m.state
}
}
}
同样的,我已将无关代码和注释删除。
解锁Unlock()的实现
func (m *Mutex) Unlock() {
// 将锁定状态置为0
new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 {
// 如果锁上存在等待者或者处于饥饿模式则进入unlockSlow()
m.unlockSlow(new)
}
}
Unlock()本身非常简单,下面重点关注下unlockSlow()的实现
func (m *Mutex) unlockSlow(new int32) {
if (new+mutexLocked)&mutexLocked == 0 {
// 如果解锁一个未锁定的锁则抛出异常
throw("sync: unlock of unlocked mutex")
}
if new&mutexStarving == 0 {
// 处于正常模式
old := new
for {
// 如果没有等待者则无需唤醒任何goroutine,另外以下三种情况也无需唤醒
// 1. 锁处于锁定状态,说明Unlock()解锁后紧接着就被其他goroutine获取,就不用再唤醒了
// 2. 锁处于唤醒状态,说明有等待的goroutine已经被唤醒了,不用再尝试唤醒了
// 3. 锁处于饥饿模式,锁会交给等待队列队头的等待者,不能往下进行
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {
return
}
// 流程走到这里说明当前有等待者并且锁处于空闲状态(三个标志位都为0)
// 说明等待者还没有被唤醒,需要唤醒等待者
// 通过CAS将等待者数量-1,并且设置为唤醒
new = (old - 1<<mutexWaiterShift) | mutexWoken
if atomic.CompareAndSwapInt32(&m.state, old, new) {
// 通过信号量唤醒等待者goroutine,然后退出
runtime_Semrelease(&m.sema, false, 1)
return
}
// CAS修改失败,说明锁的状态已经被修改,有以下几种可能性:
// 1. 有新的等待者进来
// 2. 锁被其他goroutine获取(Unlokc()中已经解锁了,走到这里可能已经被其他goroutine)
// 3. 锁进入了饥饿模式
// 更新锁状态,进入到下一个循环
old = m.state
}
} else {
// 处于饥饿模式则直接通过信号量唤醒等待队列头的goroutine
// 此时state的mutexLocked还没有加锁,唤醒的goroutine会持有锁
// 在此期间,如果有新的goroutine来请求锁, 因为mutex处于饥饿状态,不会抢占锁
runtime_Semrelease(&m.sema, true, 1)
}
}
后言
Mutex虽然代码简单,但由于并行的原因导致case太多,所以还是不太好理解了,建议大家代入到具体的场景中去分析。




 运行时,第一次循环中,CPU需要先加载x[0],由于高速缓存中一开始并没有,所以会从主存中加载x[0]-x[3]共16个字节(数据块的大小)的数据到高速缓存的
运行时,第一次循环中,CPU需要先加载x[0],由于高速缓存中一开始并没有,所以会从主存中加载x[0]-x[3]共16个字节(数据块的大小)的数据到高速缓存的
 可以看到我们只在结构体中加入了一个64字节的元素性能就得到了极大的提高,这是为什么呢?
可以看到我们只在结构体中加入了一个64字节的元素性能就得到了极大的提高,这是为什么呢? 之所以这样设计是基于电路工作效率考虑,这样的设计可以并行取8个字节的数据,如果想取址0x0000-0x0007,每个bank只需要工作一次就可以取到,IO效率比较高,如果这8个字节在同一个bank上则需要串行读取该bank8次才能取到。
之所以这样设计是基于电路工作效率考虑,这样的设计可以并行取8个字节的数据,如果想取址0x0000-0x0007,每个bank只需要工作一次就可以取到,IO效率比较高,如果这8个字节在同一个bank上则需要串行读取该bank8次才能取到。 总共占用13个字节。我们可以看到
总共占用13个字节。我们可以看到  总共占用20个字节,
总共占用20个字节, 这时总共占用16个字节,相比较上面我们节省了8个字节。
写段代码验证下:
这时总共占用16个字节,相比较上面我们节省了8个字节。
写段代码验证下: