原文地址:https://blog.fanscore.cn/a/53/
1. 前言
本文是与世界分享我刚编的转发ntunnel_mysql.php的工具的后续,之前的实现有些拉胯,这次重构了下。需求背景是为了在本地macbook上通过开源的mysql可视化客户端(dbeaver、Sequel Ace等)访问我司测试环境的mysql,整个测试环境的如图所示:
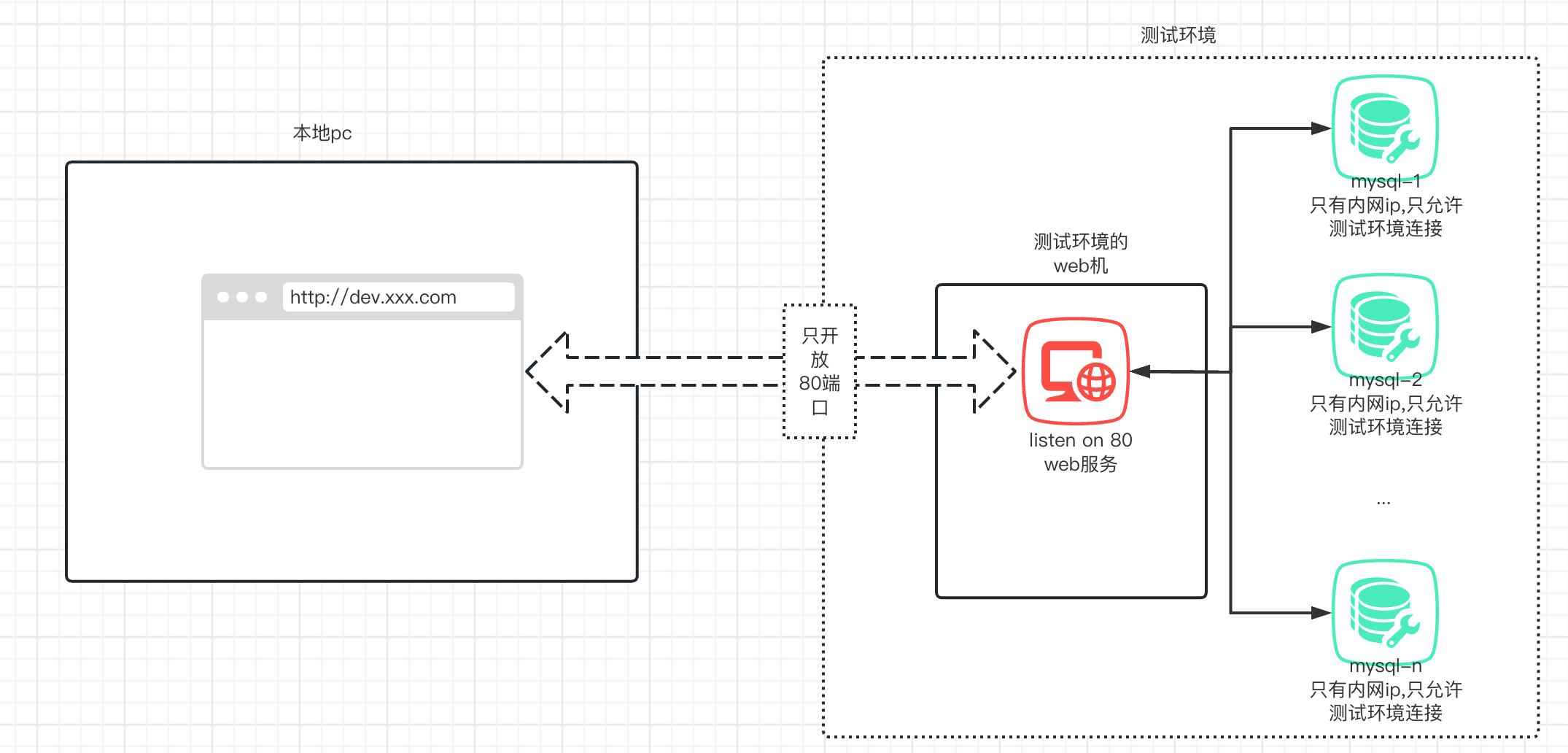
那么就有以下几种方式:
- 客户端直连mysql #Pass# 测试环境mysql只提供了内网ip,只允许测试环境上的机器连接,因此不可行
- 通过ssh隧道连接 #Pass# 测试环境机器倒是可以ssh上去,但是只能通过堡垒机接入,且堡垒机不允许ssh隧道,因此不可行
- navicat http隧道连接 #Pass# 测试环境有机器提供了公网ip开放了http服务,因此技术上是可行的,但navicat非开源免费软件,我司禁止使用,因此不可行
- 测试环境选一台机器建立mysql代理转发请求 #Pass# 测试环境机器只开放了80端口,且已被nginx占用,因此不可行
- 内网穿透 这个想法很好,下次不要再想了

既然上面的方式都不行,那怎么办呢?因此我产生了一个大胆的想法
2. 一个大胆的想法
大概架构如下
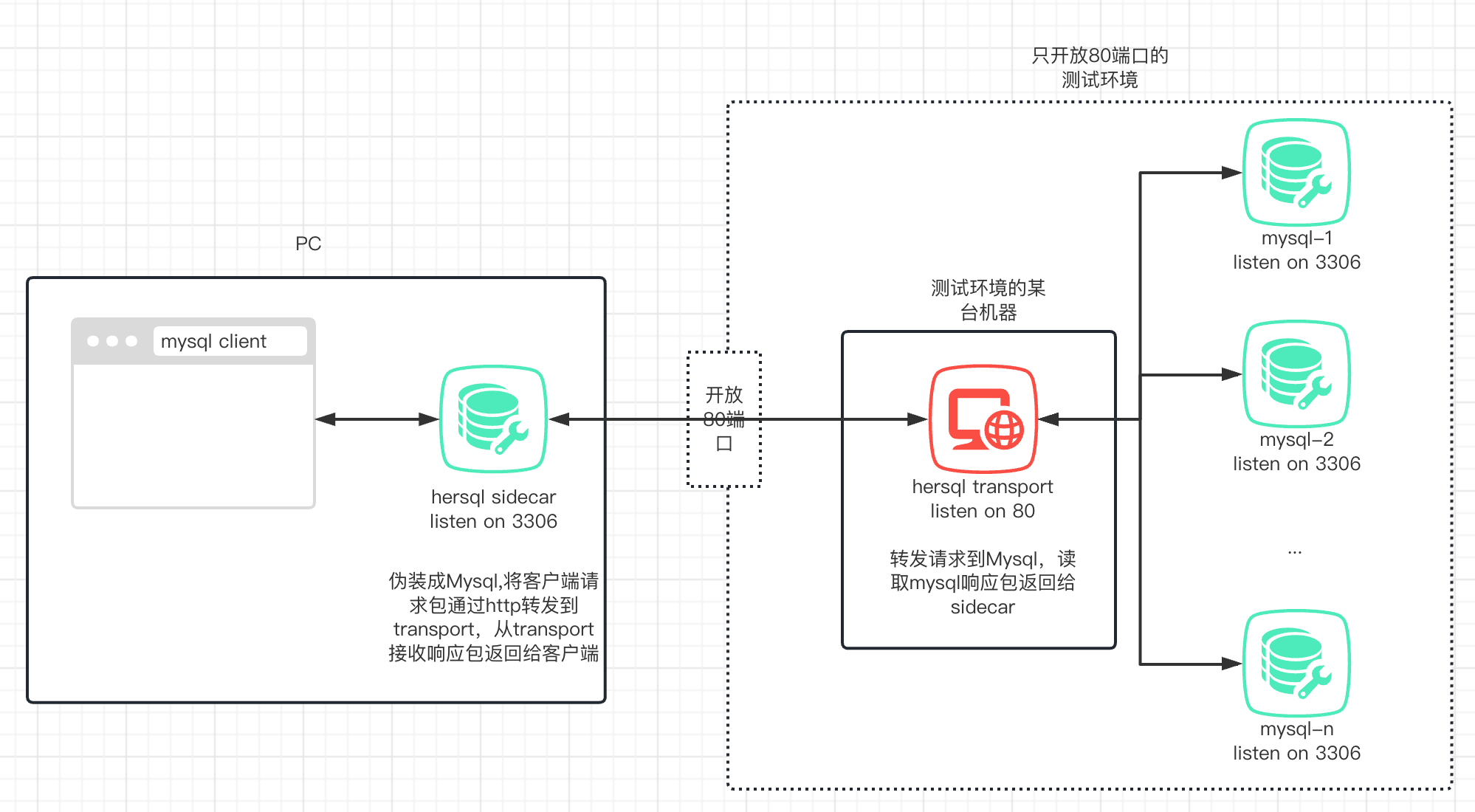
首先,在本地pc上启动一个sidecar进程,该进程监听3306端口,实现mysql协议,将自己伪装为一个mysql server。本地pc上的mysql客户端连接到sidecar,发送请求数据包给sidecar,从sidecar读取响应包。
然后在测试环境某台机器上启动transport进程,该进程启动http服务,由nginx代理转发请求,相当于监听在80端口,然后连接到测试环境的mysql server。
sidecar会将来自客户端的请求包通过http请求转发给transport,transport将请求包转发到测试环境对应的mysql server,然后读取mysql的响应数据包,然后将响应数据包返回给sidecar,sidecar再将响应包返回给mysql客户端。
遵循上述的基本原理,我将其实现出来: https://github.com/Orlion/hersql。但是在描述hersql的实现细节之前我们有必要了解下mysql协议
3. mysql协议
mysql客户端与服务端交互过程主要分为两个阶段:握手阶段与命令阶段。交互流程如下:
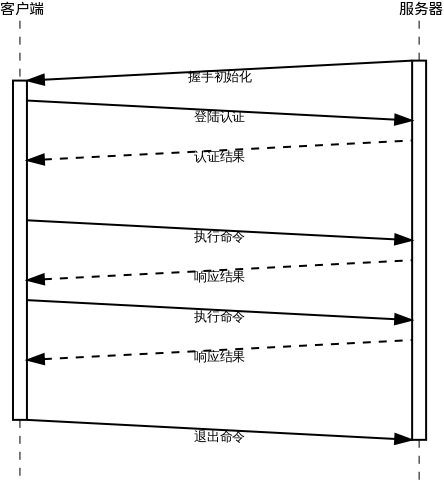
在最新版本中,握手过程比上面要复杂,会多几次交互
3.1 握手阶段
在握手阶段,3次握手建立tcp连接后服务端会首先发送一个握手初始化包,包含了 * 协议版本号:指示所使用的协议版本。 * 服务器版本:指示MySQL服务器版本的字符串。 * 连接ID:在当前连接中唯一标识客户端的整数。 * 随机数据:包含一个随机字符串,用于后续的身份验证。 * 服务器支持的特性标志:指示服务器支持的客户端功能的位掩码。 * 字符集:指示服务器使用的默认字符集。 * 默认的身份验证插件名(低版本没有该数据)
随后客户端会发送一个登录认证包,包含了:
- 协议版本号:指示所使用的协议版本。
- 用户名:用于身份验证的用户名。
- 加密密码:客户端使用服务端返回的随机数对密码进行加密
- 数据库名称:连接后要使用的数据库名称。
- 客户端标志:客户端支持的功能的位掩码。
- 最大数据包大小:客户端希望接收的最大数据包大小。
- 字符集:客户端希望使用的字符集。
- 插件名称:客户端希望使用的身份验证插件的名称。
服务端收到客户端发来的登录认证包验证通过后会发送一个OK包,告知客户端连接成功,可以转入命令交互阶段
在mysql 8.0默认的身份验证插件为
caching_sha2_password,低版本为mysql_native_password,两者的验证交互流程有所不同个,caching_sha2_password在缓存未命中的情况下还会多几次交互。另外如果服务端与客户端的验证插件不同的话,也是会多几次交互。
3.2 命令阶段
在命令阶段,客户端会发送命令请求包到服务端。数据包的第一个字节标识了当前请求的类型,常见的命令有:
- COM_QUERY命令,执行SQL查询语句。
- COM_INIT_DB命令,连接到指定的数据库。
- COM_QUIT命令,关闭MySQL连接。
- COM_FIELD_LIST命令,列出指定表的字段列表。
- COM_PING命令,向MySQL服务器发送PING请求。
- COM_STMT_系列预处理语句命令
请求响应的模式是客户端会发一个请求包,服务端会回复n(n>=0)个响应包
最后客户端断开连接时会主动发送一个COM_QUIT命令包通知服务端断开连接
4. hersql数据流转过程
在了解mysql协议之后我们就可以来看下hersql的数据流转过程了。
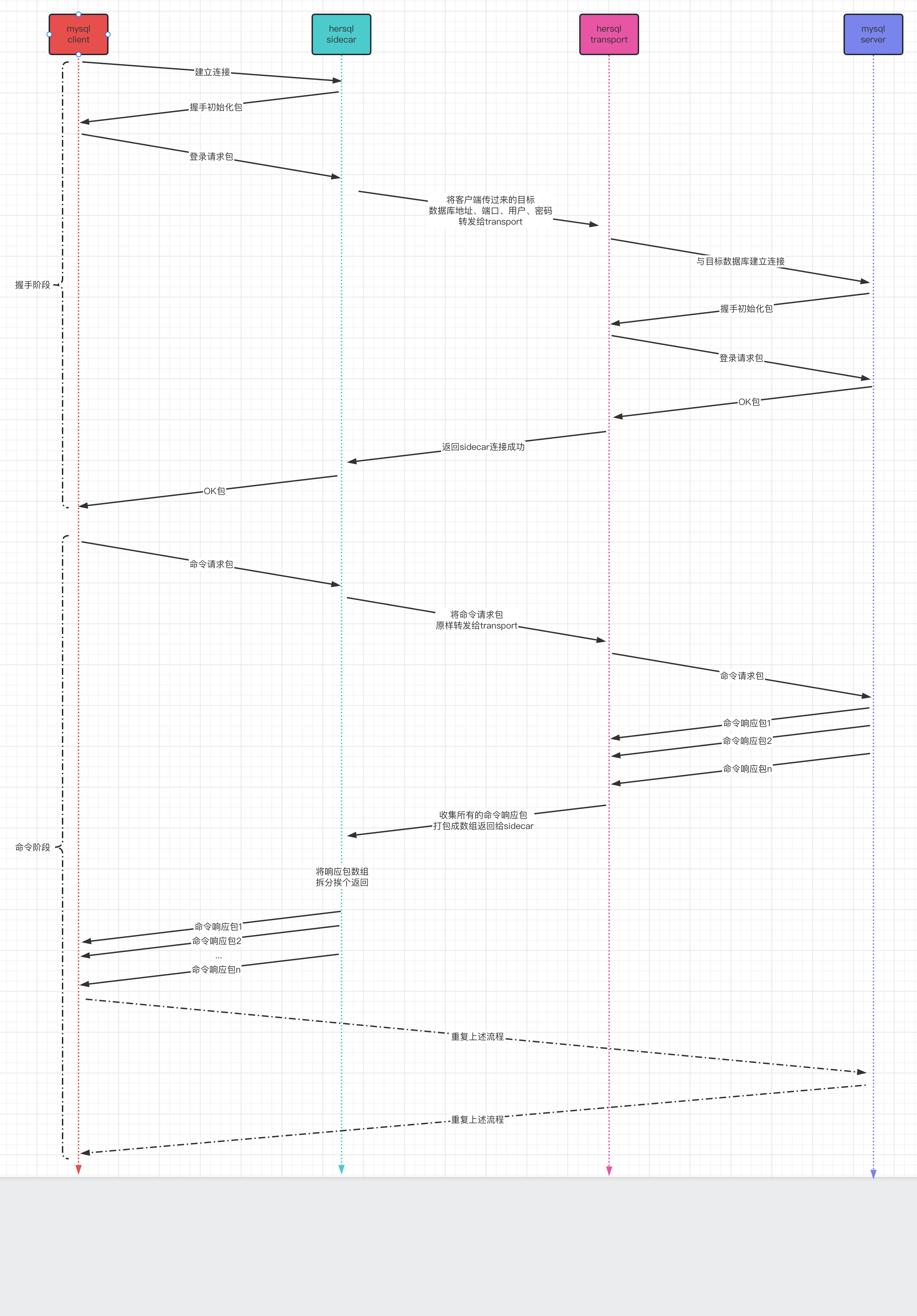
transport连接mysql server时必须要知道目标数据库的地址与端口号(mysql client连接的是sidecar),所以hersql要求mysql client需要在数据库名中携带目标数据库的地址与端口号。
transport发给mysql server的登录请求包中需要包含用mysql server发来的随机数加密之后的密码,但是mysql client给到sidecar的登录请求包中的密码是用sidecar给的随机数加密的,因此无法直接拿来使用,所以hersql要求mysql client需要在数据库名中携带密码原文,transport会用mysql server给的随机数进行加密, 这也是hersql的局限。
5. hersql使用
上面介绍了一堆原理性的东西,那么如何使用呢?
5.1 在一台能够请求目标mysql server的机器上部署hersql transport
首先你需要下载下来hersql的源码:https://github.com/Orlion/hersql,还需要安装下golang,这些都完成后你就可以启动hersql transport了。但是先别着急,我先解释下transport的配置文件tranport.example.yaml:
server:
# transport http服务监听的地址
addr: :8080
log:
# 标准输出的日志的日志级别
stdout_level: debug
# 文件日志的日志级别
level: error
# 文件日志的文件地址
filename: ./storage/transport.log
# 日志文件的最大大小(以MB为单位), 默认为 100MB。日志文件超过此大小会创建个新文件继续写入
maxsize: 100
# maxage 是根据文件名中编码的时间戳保留旧日志文件的最大天数。
maxage: 168
# maxbackups 是要保留的旧日志文件的最大数量。默认是保留所有旧日志文件。
maxbackups: 3
# 是否应使用 gzip 压缩旋转的日志文件。默认是不执行压缩。
compress: false
你可以根据你的需求修改配置,然后就可以启动transport了
$ go run cmd/transport/main.go -conf=transport.example.yaml
一般情况下都是会先编译为可执行文件,由systemd之类的工具托管transport进程,保证transport存活。这里简单期间直接用go run起来
5.2 在你本地机器部署启动hersql sidecar
同样的,你需要下载下来hersql的源码:https://github.com/Orlion/hersql,提前安装好golang。修改下sidecar的配置文件sidecar.example.yaml:
server:
# sidecar 监听的地址,之后mysql client会连接这个地址
addr: 127.0.0.1:3306
# transport http server的地址
transport_addr: http://x.x.x.x:xxxx
log:
# 与transport配置相同
就可以启动sidecar了
$ go run cmd/sidecar/main.go -conf=sidecar.example.yaml
同样的,一般情况下也都是会先编译为可执行文件,mac上是launchctl之类的工具托管sidecar进程,保证sidecar存活。这里简单期间直接用go run起来
5.3 客户端连接
上面的步骤都执行完成后,就可以打开mysql客户端使用了。数据库地址和端口号需要填写sidecar配置文件中的addr地址,sidercar不会校验用户名和密码,因此用户名密码可以随意填写
重点来了: 数据库名必须要填写,且必须要按照以下格式填写
[username[:password]@][protocol[(address)]]/dbname[?param1=value1&...¶mN=valueN]
举个例子:
root:123456@tcp(10.10.123.123:3306)/BlogDB
如图所示:
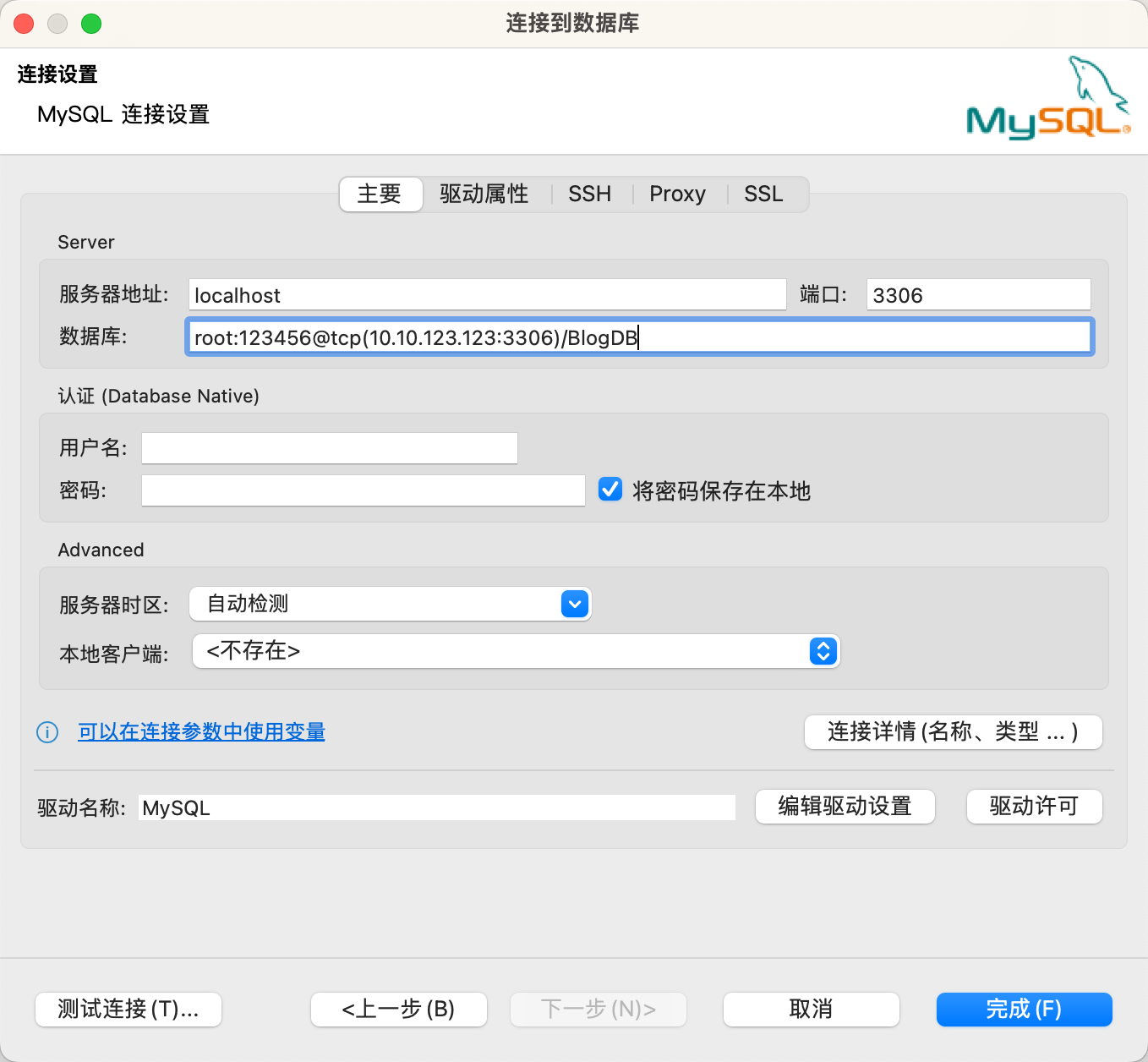
5.4 举个例子
目标mysql服务器
- 地址:10.10.123.123:3306
- 数据库:BlogDB
- 用户名:root
- 密码:123456
可以直连目标mysql服务器的机器
- 地址:10.10.123.100
- 开放端口:8080
那么transport可以配置为
server:
addr: :8080
sidecar可以配置为
server:
addr: 127.0.0.1:3306
transport_addr: http://10.10.123.100:8080
客户端连接配置
- 服务器地址:127.0.0.1
- 端口: 3306
- 数据库名
root:123456@tcp(10.10.123.123:3306)/BlogDB
5.5 局限
hersql目前只支持mysql_native_password的认证方式,mysql8默认的认证方式是caching_sha2_password,所以如果要通过hersql连接mysql8需要注意登录用户的认证方式是否是mysql_native_password,如果是caching_sha2_password那暂时是无法使用的。
6. 参考资料
如果hersql对你有帮助欢迎点个star





